
SpringBoot讲义-开发实用篇
# SpringBoot 开发实用篇
# 前言(白嫖发言)
这个笔记是从黑马老师那里嫖来的,放在这里是为了方便查看,没有商用的意思,转载请标明黑马程序员以及链接。
黑马程序员 SpringBoot2 全套视频教程,springboot 零基础到项目实战
开发实用篇中因为牵扯到 SpringBoot 整合各种各样的技术,由于不是每个小伙伴对各种技术都有所掌握,所以在整合每一个技术之前,都会做一个快速的普及,这样的话内容整个开发实用篇所包含的内容就会比较多。各位小伙伴在学习的时候,如果对某一个技术不是很清楚,可以先跳过对应章节,或者先补充一下技术知识,然后再来看对应的课程。开发实用篇具体包含的内容如下:
- 热部署
- 配置高级
- 测试
- 数据层解决方案
- 整合第三方技术
- 监控
看目录感觉内容量并不是很大,但是在数据层解决方案和整合第三方技术中包含了大量的知识,一点一点慢慢学吧。下面开启第一部分热部署相关知识的学习
# KF-1. 热部署
什么是热部署?简单说就是你程序改了,现在要重新启动服务器,嫌麻烦?不用重启,服务器会自己悄悄的把更新后的程序给重新加载一遍,这就是热部署。
热部署的功能是如何实现的呢?这就要分两种情况来说了,非 springboot 工程和 springboot 工程的热部署实现方式完全不一样。先说一下原始的非 springboot 项目是如何实现热部署的。
非 springboot 项目热部署实现原理
开发非 springboot 项目时,我们要制作一个 web 工程并通过 tomcat 启动,通常需要先安装 tomcat 服务器到磁盘中,开发的程序配置发布到安装的 tomcat 服务器上。如果想实现热部署的效果,这种情况其实有两种做法,一种是在 tomcat 服务器的配置文件中进行配置,这种做法与你使用什么 IDE 工具无关,不管你使用 eclipse 还是 idea 都行。还有一种做法是通过 IDE 工具进行配置,比如在 idea 工具中进行设置,这种形式需要依赖 IDE 工具,每款 IDE 工具不同,对应的配置也不太一样。但是核心思想是一样的,就是使用服务器去监控其中加载的应用,发现产生了变化就重新加载一次。
上面所说的非 springboot 项目实现热部署看上去是一个非常简单的过程,几乎每个小伙伴都能自己写出来。如果你不会写,我给你个最简单的思路,但是实际设计要比这复杂一些。例如启动一个定时任务,任务启动时记录每个文件的大小,以后每 5 秒比对一下每个文件的大小是否有改变,或者是否有新文件。如果没有改变,放行,如果有改变,刷新当前记录的文件信息,然后重新启动服务器,这就可以实现热部署了。当然,这个过程肯定不能这么做,比如我把一个打印输出的字符串 "abc" 改成 "cba",比对大小是没有变化的,但是内容缺实变了,所以这么做肯定不行,只是给大家打个比方,而且重启服务器这就是冷启动了,不能算热部署,领会精神吧。
看上去这个过程也没多复杂,在 springboot 项目中难道还有其他的弯弯绕吗?还真有。
springboot 项目热部署实现原理
基于 springboot 开发的 web 工程其实有一个显著的特征,就是 tomcat 服务器内置了,还记得内嵌服务器吗?服务器是以一个对象的形式在 spring 容器中运行的。本来我们期望于 tomcat 服务器加载程序后由 tomcat 服务器盯着程序,你变化后我就重新启动重新加载,但是现在 tomcat 和我们的程序是平级的了,都是 spring 容器中的组件,这下就麻烦了,缺乏了一个直接的管理权,那该怎么做呢?简单,再搞一个程序 X 在 spring 容器中盯着你原始开发的程序 A 不就行了吗?确实,搞一个盯着程序 A 的程序 X 就行了,如果你自己开发的程序 A 变化了,那么程序 X 就命令 tomcat 容器重新加载程序 A 就 OK 了。并且这样做有一个好处,spring 容器中东西不用全部重新加载一遍,只需要重新加载你开发的程序那一部分就可以了,这下效率又高了,挺好。
下面就说说,怎么搞出来这么一个程序 X,肯定不是我们自己手写了,springboot 早就做好了,搞一个坐标导入进去就行了。
# KF-1-1. 手动启动热部署
步骤①:导入开发者工具对应的坐标
1 | <dependency> |
步骤②:构建项目,可以使用快捷键激活此功能
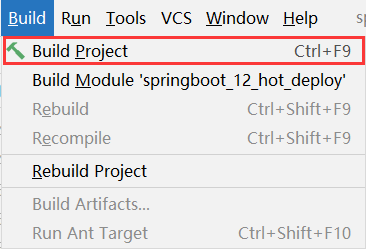
对应的快捷键一定要记得
1 | <CTR>L+<F9> |
以上过程就实现了 springboot 工程的热部署,是不是挺简单的。不过这里需要把底层的工作工程给普及一下。
重启与重载
一个 springboot 项目在运行时实际上是分两个过程进行的,根据加载的东西不同,划分成 base 类加载器与 restart 类加载器。
- base 类加载器:用来加载 jar 包中的类,jar 包中的类和配置文件由于不会发生变化,因此不管加载多少次,加载的内容不会发生变化
- restart 类加载器:用来加载开发者自己开发的类、配置文件、页面等信息,这一类文件受开发者影响
当 springboot 项目启动时,base 类加载器执行,加载 jar 包中的信息后,restart 类加载器执行,加载开发者制作的内容。当执行构建项目后,由于 jar 中的信息不会变化,因此 base 类加载器无需再次执行,所以仅仅运行 restart 类加载即可,也就是将开发者自己制作的内容重新加载就行了,这就完成了一次热部署的过程,也可以说热部署的过程实际上是重新加载 restart 类加载器中的信息。
总结
- 使用开发者工具可以为当前项目开启热部署功能
- 使用构建项目操作对工程进行热部署
思考
上述过程每次进行热部署都需要开发者手工操作,不管是点击按钮还是快捷键都需要开发者手工执行。这种操作的应用场景主要是在开发调试期,并且调试的代码处于不同的文件中,比如服务器启动了,我需要改 4 个文件中的内容,然后重启,等 4 个文件都改完了再执行热部署,使用一个快捷键就 OK 了。但是如果现在开发者要修改的内容就只有一个文件中的少量代码,这个时候代码修改完毕如果能够让程序自己执行热部署功能,就可以减少开发者的操作,也就是自动进行热部署,能这么做吗?是可以的。咱们下一节再说。
# KF-1-2. 自动启动热部署
自动热部署其实就是设计一个开关,打开这个开关后,IDE 工具就可以自动热部署。因此这个操作和 IDE 工具有关,以下以 idea 为例设置 idea 中启动热部署
步骤①:设置自动构建项目
打开【File】,选择【settings…】, 在面板左侧的菜单中找到【Compile】选项,然后勾选【Build project automatically】,意思是自动构建项目
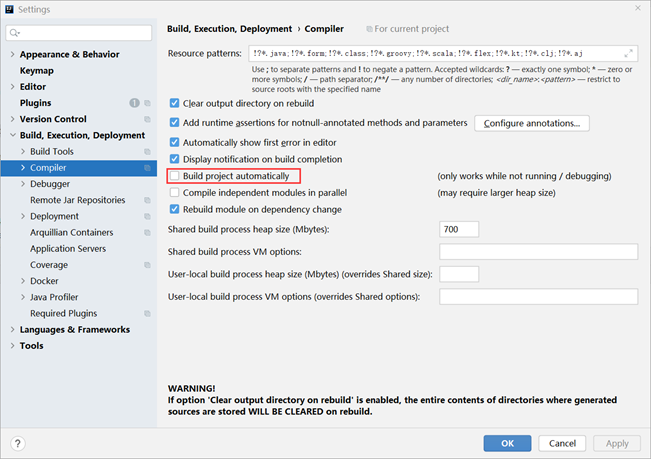
自动构建项目选项勾选后
步骤②:允许在程序运行时进行自动构建
使用快捷键【Ctrl】+【Alt】+【Shit】+【/】打开维护面板,选择第 1 项【Registry…】
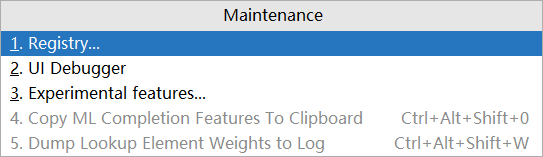
在选项中搜索 comple,然后勾选对应项即可
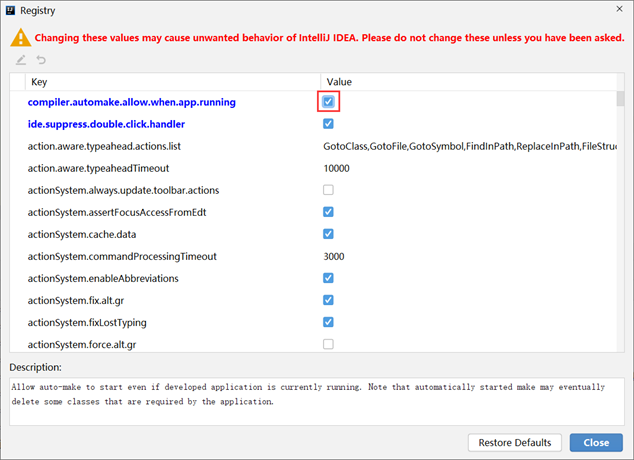
这样程序在运行的时候就可以进行自动构建了,实现了热部署的效果。
关注:如果你每敲一个字母,服务器就重新构建一次,这未免有点太频繁了,所以 idea 设置当 idea 工具失去焦点 5 秒后进行热部署。其实就是你从 idea 工具中切换到其他工具时进行热部署,比如改完程序需要到浏览器上去调试,这个时候 idea 就自动进行热部署操作。
总结
- 自动热部署要开启自动构建项目
- 自动热部署要开启在程序运行时自动构建项目
思考
现在已经实现了热部署了,但是到企业开发的时候你会发现,为了便于管理,在你的程序目录中除了有代码,还有可能有文档,如果你修改了一下文档,这个时候会进行热部署吗?不管是否进行热部署,这个过程我们需要自己控制才比较合理,那这个东西能控制吗?咱们下一节再说。
# KF-1-3. 参与热部署监控的文件范围配置
通过修改项目中的文件,你可以发现其实并不是所有的文件修改都会激活热部署的,原因在于在开发者工具中有一组配置,当满足了配置中的条件后,才会启动热部署,配置中默认不参与热部署的目录信息如下
- /META-INF/maven
- /META-INF/resources
- /resources
- /static
- /public
- /templates
以上目录中的文件如果发生变化,是不参与热部署的。如果想修改配置,可以通过 application.yml 文件进行设定哪些文件不参与热部署操作
1 | spring: |
总结
- 通过配置可以修改不参与热部署的文件或目录
思考
热部署功能是一个典型的开发阶段使用的功能,到了线上环境运行程序时,这个功能就没有意义了。能否关闭热部署功能呢?咱们下一节再说。
# KF-1-4. 关闭热部署
线上环境运行时是不可能使用热部署功能的,所以需要强制关闭此功能,通过配置可以关闭此功能。
1 | spring: |
如果当心配置文件层级过多导致相符覆盖最终引起配置失效,可以提高配置的层级,在更高层级中配置关闭热部署。例如在启动容器前通过系统属性设置关闭热部署功能。
1 |
|
其实上述担心略微有点多余,因为线上环境的维护是不可能出现修改代码的操作的,这么做唯一的作用是降低资源消耗,毕竟那双盯着你项目是不是产生变化的眼睛只要闭上了,就不具有热部署功能了,这个开关的作用就是禁用对应功能。
总结
- 通过配置可以关闭热部署功能降低线上程序的资源消耗
# KF-2. 配置高级
进入开发实用篇第二章内容,配置高级,其实配置在基础篇讲了一部分,在运维实用篇讲了一部分,这里还要讲,讲的东西有什么区别呢?距离开发过程越来越接近,解决的问题也越来越靠近线上环境,下面就开启本章的学习。
# KF-2-1.@ConfigurationProperties
在基础篇学习了 @ConfigurationProperties 注解,此注解的作用是用来为 bean 绑定属性的。开发者可以在 yml 配置文件中以对象的格式添加若干属性
1 | servers: |
然后再开发一个用来封装数据的实体类,注意要提供属性对应的 setter 方法
1 |
|
使用 @ConfigurationProperties 注解就可以将配置中的属性值关联到开发的模型类上
1 |
|
这样加载对应 bean 的时候就可以直接加载配置属性值了。但是目前我们学的都是给自定义的 bean 使用这种形式加载属性值,如果是第三方的 bean 呢?能不能用这种形式加载属性值呢?为什么会提出这个疑问?原因就在于当前 @ConfigurationProperties 注解是写在类定义的上方,而第三方开发的 bean 源代码不是你自己书写的,你也不可能到源代码中去添加 @ConfigurationProperties 注解,这种问题该怎么解决呢?下面就来说说这个问题。
使用 @ConfigurationProperties 注解其实可以为第三方 bean 加载属性,格式特殊一点而已。
步骤①:使用 @Bean 注解定义第三方 bean
1 |
|
步骤②:在 yml 中定义要绑定的属性,注意 datasource 此时全小写
1 | datasource: |
步骤③:使用 @ConfigurationProperties 注解为第三方 bean 进行属性绑定,注意前缀是全小写的 datasource
1 |
|
操作方式完全一样,只不过 @ConfigurationProperties 注解不仅能添加到类上,还可以添加到方法上,添加到类上是为 spring 容器管理的当前类的对象绑定属性,添加到方法上是为 spring 容器管理的当前方法的返回值对象绑定属性,其实本质上都一样。
做到这其实就出现了一个新的问题,目前我们定义 bean 不是通过类注解定义就是通过 @Bean 定义,使用 @ConfigurationProperties 注解可以为 bean 进行属性绑定,那在一个业务系统中,哪些 bean 通过注解 @ConfigurationProperties 去绑定属性了呢?因为这个注解不仅可以写在类上,还可以写在方法上,所以找起来就比较麻烦了。为了解决这个问题,spring 给我们提供了一个全新的注解,专门标注使用 @ConfigurationProperties 注解绑定属性的 bean 是哪些。这个注解叫做 @EnableConfigurationProperties。具体如何使用呢?
步骤①:在配置类上开启 @EnableConfigurationProperties 注解,并标注要使用 @ConfigurationProperties 注解绑定属性的类
1 | @SpringBootApplication |
步骤②:在对应的类上直接使用 @ConfigurationProperties 进行属性绑定
1 |
|
有人感觉这没区别啊?注意观察,现在绑定属性的 ServerConfig 类并没有声明 @Component 注解。当使用 @EnableConfigurationProperties 注解时,spring 会默认将其标注的类定义为 bean,因此无需再次声明 @Component 注解了。
最后再说一个小技巧,使用 @ConfigurationProperties 注解时,会出现一个提示信息

出现这个提示后只需要添加一个坐标此提醒就消失了
1 | <dependency> |
总结
- 使用 @ConfigurationProperties 可以为使用 @Bean 声明的第三方 bean 绑定属性
- 当使用 @EnableConfigurationProperties 声明进行属性绑定的 bean 后,无需使用 @Component 注解再次进行 bean 声明
# KF-2-2. 宽松绑定 / 松散绑定
在进行属性绑定时,可能会遇到如下情况,为了进行标准命名,开发者会将属性名严格按照驼峰命名法书写,在 yml 配置文件中将 datasource 修改为 dataSource,如下:
1 | dataSource: |
此时程序可以正常运行,然后又将代码中的前缀 datasource 修改为 dataSource,如下:
1 |
|
此时就发生了编译错误,而且并不是 idea 工具导致的,运行后依然会出现问题,配置属性名 dataSource 是无效的
1 | Configuration property name 'dataSource' is not valid: |
为什么会出现这种问题,这就要来说一说 springboot 进行属性绑定时的一个重要知识点了,有关属性名称的宽松绑定,也可以称为宽松绑定。
什么是宽松绑定?实际上是 springboot 进行编程时人性化设计的一种体现,即配置文件中的命名格式与变量名的命名格式可以进行格式上的最大化兼容。兼容到什么程度呢?几乎主流的命名格式都支持,例如:
在 ServerConfig 中的 ipAddress 属性名
1 |
|
可以与下面的配置属性名规则全兼容
1 | servers: |
也可以说,以上 4 种模式最终都可以匹配到 ipAddress 这个属性名。为什么这样呢?原因就是在进行匹配时,配置中的名称要去掉中划线和下划线后,忽略大小写的情况下去与 java 代码中的属性名进行忽略大小写的等值匹配,以上 4 种命名去掉下划线中划线忽略大小写后都是一个词 ipaddress,java 代码中的属性名忽略大小写后也是 ipaddress,这样就可以进行等值匹配了,这就是为什么这 4 种格式都能匹配成功的原因。不过 springboot 官方推荐使用烤肉串模式,也就是中划线模式。
到这里我们掌握了一个知识点,就是命名的规范问题。再来看开始出现的编程错误信息
1 | Configuration property name 'dataSource' is not valid: |
其中 Reason 描述了报错的原因,规范的名称应该是烤肉串 (kebab) 模式 (case),即使用 - 分隔,使用小写字母数字作为标准字符,且必须以字母开头。然后再看我们写的名称 dataSource,就不满足上述要求。闹了半天,在书写前缀时,这个词不是随意支持的,必须使用上述标准。编程写了这么久,基本上编程习惯都养成了,到这里又被 springboot 教育了,没辙,谁让人家东西好用呢,按照人家的要求写吧。
最后说一句,以上规则仅针对 springboot 中 @ConfigurationProperties 注解进行属性绑定时有效,对 @Value 注解进行属性映射无效。有人就说,那我不用你不就行了?不用,你小看 springboot 的推广能力了,到原理篇我们看源码时,你会发现内部全是这玩意儿,算了,拿人手短吃人嘴短,认怂吧。
总结
- @ConfigurationProperties 绑定属性时支持属性名宽松绑定,这个宽松体现在属性名的命名规则上
- @Value 注解不支持松散绑定规则
- 绑定前缀名推荐采用烤肉串命名规则,即使用中划线做分隔符
# KF-2-3. 常用计量单位绑定
在前面的配置中,我们书写了如下配置值,其中第三项超时时间 timeout 描述了服务器操作超时时间,当前值是 - 1 表示永不超时。
1 | servers: |
但是每个人都这个值的理解会产生不同,比如线上服务器完成一次主从备份,配置超时时间 240,这个 240 如果单位是秒就是超时时间 4 分钟,如果单位是分钟就是超时时间 4 小时。面对一次线上服务器的主从备份,设置 4 分钟,简直是开玩笑,别说拷贝过程,备份之前的压缩过程 4 分钟也搞不定,这个时候问题就来了,怎么解决这个误会?
除了加强约定之外,springboot 充分利用了 JDK8 中提供的全新的用来表示计量单位的新数据类型,从根本上解决这个问题。以下模型类中添加了两个 JDK8 中新增的类,分别是 Duration 和 DataSize
1 |
|
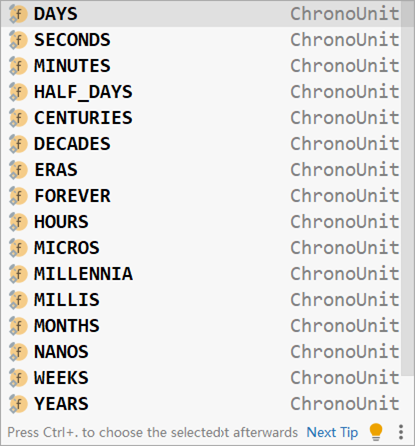
Duration:表示时间间隔,可以通过 @DurationUnit 注解描述时间单位,例如上例中描述的单位为小时(ChronoUnit.HOURS)
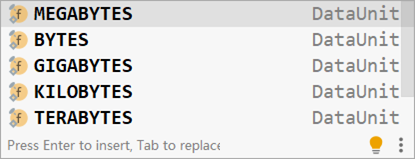
DataSize:表示存储空间,可以通过 @DataSizeUnit 注解描述存储空间单位,例如上例中描述的单位为 MB(DataUnit.MEGABYTES)
使用上述两个单位就可以有效避免因沟通不同步或文档不健全导致的信息不对称问题,从根本上解决了问题,避免产生误读。
Druation 常用单位如下:
DataSize 常用单位如下:
# KF-2-4. 校验
目前我们在进行属性绑定时可以通过松散绑定规则在书写时放飞自我了,但是在书写时由于无法感知模型类中的数据类型,就会出现类型不匹配的问题,比如代码中需要 int 类型,配置中给了非法的数值,例如写一个 “a",这种数据肯定无法有效的绑定,还会引发错误。 SpringBoot 给出了强大的数据校验功能,可以有效的避免此类问题的发生。在 JAVAEE 的 JSR303 规范中给出了具体的数据校验标准,开发者可以根据自己的需要选择对应的校验框架,此处使用 Hibernate 提供的校验框架来作为实现进行数据校验。书写应用格式非常固定,话不多说,直接上步骤
步骤①:开启校验框架
1 | <!--1.导入JSR303规范--> |
步骤②:在需要开启校验功能的类上使用注解 @Validated 开启校验功能
1 |
|
步骤③:对具体的字段设置校验规则
1 |
|
通过设置数据格式校验,就可以有效避免非法数据加载,其实使用起来还是挺轻松的,基本上就是一个格式。
总结
- 开启 Bean 属性校验功能一共 3 步:导入 JSR303 与 Hibernate 校验框架坐标、使用 @Validated 注解启用校验功能、使用具体校验规则规范数据校验格式
# KF-2-5. 数据类型转换
有关 spring 属性注入的问题到这里基本上就讲完了,但是最近一名开发者向我咨询了一个问题,我觉得需要给各位学习者分享一下。在学习阶段其实我们遇到的问题往往复杂度比较低,单一性比较强,但是到了线上开发时,都是综合性的问题,而这个开发者遇到的问题就是由于 bean 的属性注入引发的灾难。
先把问题描述一下,这位开发者连接数据库正常操作,但是运行程序后显示的信息是密码错误。
1 | java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES) |
其实看到这个报错,几乎所有的学习者都能分辨出来,这是用户名和密码不匹配,就就是密码输入错了,但是问题就在于密码并没有输入错误,这就比较讨厌了。给的报错信息无法帮助你有效的分析问题,甚至会给你带到沟里。如果是初学者,估计这会心态就崩了,我密码没错啊,你怎么能说我有错误呢?来看看用户名密码的配置是如何写的:
1 | spring: |
这名开发者的生日是 1 月 27 日,所以密码就使用了 0127,其实问题就出在这里了。
之前在基础篇讲属性注入时,提到过类型相关的知识,在整数相关知识中有这么一句话,支持二进制,八进制,十六进制

这个问题就处在这里了,因为 0127 在开发者眼中是一个字符串 “0127”,但是在 springboot 看来,这就是一个数字,而且是一个八进制的数字。当后台使用 String 类型接收数据时,如果配置文件中配置了一个整数值,他是先安装整数进行处理,读取后再转换成字符串。巧了,0127 撞上了八进制的格式,所以最终以十进制数字 87 的结果存在了。
这里提两个注意点,第一,字符串标准书写加上引号包裹,养成习惯,第二,遇到 0 开头的数据多注意吧。
总结
- yaml 文件中对于数字的定义支持进制书写格式,如需使用字符串请使用引号明确标注
# KF-3. 测试
说完 bean 配置相关的内容,下面要对前面讲过的一个知识做加强了,测试。测试是保障程序正确性的唯一屏障,在企业级开发中更是不可缺少,但是由于测试代码往往不产生实际效益,所以一些小型公司并不是很关注,导致一些开发者从小型公司进入中大型公司后,往往这一块比较短板,所以还是要拿出来把这一块知识好好说说,做一名专业的开发人员。
# KF-3-1. 加载测试专用属性
测试过程本身并不是一个复杂的过程,但是很多情况下测试时需要模拟一些线上情况,或者模拟一些特殊情况。如果当前环境按照线上环境已经设定好了,例如是下面的配置
1 | env: |
但是你现在想测试对应的兼容性,需要测试如下配置
1 | env: |
这个时候我们能不能每次测试的时候都去修改源码 application.yml 中的配置进行测试呢?显然是不行的。每次测试前改过来,每次测试后改回去,这太麻烦了。于是我们就想,需要在测试环境中创建一组临时属性,去覆盖我们源码中设定的属性,这样测试用例就相当于是一个独立的环境,能够独立测试,这样就方便多了。
临时属性
springboot 已经为我们开发者早就想好了这种问题该如何解决,并且提供了对应的功能入口。在测试用例程序中,可以通过对注解 @SpringBootTest 添加属性来模拟临时属性,具体如下:
1 | //properties属性可以为当前测试用例添加临时的属性配置 |
使用注解 @SpringBootTest 的 properties 属性就可以为当前测试用例添加临时的属性,覆盖源码配置文件中对应的属性值进行测试。
临时参数
除了上述这种情况,在前面讲解使用命令行启动 springboot 程序时讲过,通过命令行参数也可以设置属性值。而且线上启动程序时,通常都会添加一些专用的配置信息。作为运维人员他们才不懂 java,更不懂这些配置的信息具体格式该怎么写,那如果我们作为开发者提供了对应的书写内容后,能否提前测试一下这些配置信息是否有效呢?当时是可以的,还是通过注解 @SpringBootTest 的另一个属性来进行设定。
1 | //args属性可以为当前测试用例添加临时的命令行参数 |
使用注解 @SpringBootTest 的 args 属性就可以为当前测试用例模拟命令行参数并进行测试。
说到这里,好奇宝宝们肯定就有新问题了,如果两者共存呢?其实如果思考一下配置属性与命令行参数的加载优先级,这个结果就不言而喻了。在属性加载的优先级设定中,有明确的优先级设定顺序,还记得下面这个顺序吗?

在这个属性加载优先级的顺序中,明确规定了命令行参数的优先级排序是 11,而配置属性的优先级是 3,结果不言而喻了,args 属性配置优先于 properties 属性配置加载。
到这里我们就掌握了如果在测试用例中去模拟临时属性的设定。
总结
- 加载测试临时属性可以通过注解 @SpringBootTest 的 properties 和 args 属性进行设定,此设定应用范围仅适用于当前测试用例
思考
应用于测试环境的临时属性解决了,如果想在测试的时候临时加载一些 bean 能不做呢?也就是说我测试时,想搞一些独立的 bean 出来,专门应用于测试环境,能否实现呢?咱们下一节再讲。
# KF-3-2. 加载测试专用配置
上一节提出了临时配置一些专用于测试环境的 bean 的需求,这一节我们就来解决这个问题。
学习过 Spring 的知识,我们都知道,其实一个 spring 环境中可以设置若干个配置文件或配置类,若干个配置信息可以同时生效。现在我们的需求就是在测试环境中再添加一个配置类,然后启动测试环境时,生效此配置就行了。其实做法和 spring 环境中加载多个配置信息的方式完全一样。具体操作步骤如下:
步骤①:在测试包 test 中创建专用的测试环境配置类
1 |
|
上述配置仅用于演示当前实验效果,实际开发可不能这么注入 String 类型的数据
步骤②:在启动测试环境时,导入测试环境专用的配置类,使用 @Import 注解即可实现
1 |
|
到这里就通过 @Import 属性实现了基于开发环境的配置基础上,对配置进行测试环境的追加操作,实现了 1+1 的配置环境效果。这样我们就可以实现每一个不同的测试用例加载不同的 bean 的效果,丰富测试用例的编写,同时不影响开发环境的配置。
总结
- 定义测试环境专用的配置类,然后通过 @Import 注解在具体的测试中导入临时的配置,例如测试用例,方便测试过程,且上述配置不影响其他的测试类环境
思考
当前我们已经可以实现业务层和数据层的测试,并且通过临时配置,控制每个测试用例加载不同的测试数据。但是实际企业开发不仅要保障业务层与数据层的功能安全有效,也要保障表现层的功能正常。但是我们目的对表现层的测试都是通过 postman 手工测试的,并没有在打包过程中体现表现层功能被测试通过。能否在测试用例中对表现层进行功能测试呢?还真可以,咱们下一节再讲。
# KF-3-3.Web 环境模拟测试
在测试中对表现层功能进行测试需要一个基础和一个功能。所谓的一个基础是运行测试程序时,必须启动 web 环境,不然没法测试 web 功能。一个功能是必须在测试程序中具备发送 web 请求的能力,不然无法实现 web 功能的测试。所以在测试用例中测试表现层接口这项工作就转换成了两件事,一,如何在测试类中启动 web 测试,二,如何在测试类中发送 web 请求。下面一件事一件事进行,先说第一个
测试类中启动 web 环境
每一个 springboot 的测试类上方都会标准 @SpringBootTest 注解,而注解带有一个属性,叫做 webEnvironment。通过该属性就可以设置在测试用例中启动 web 环境,具体如下:
1 |
|
测试类中启动 web 环境时,可以指定启动的 Web 环境对应的端口,springboot 提供了 4 种设置值,分别如下:
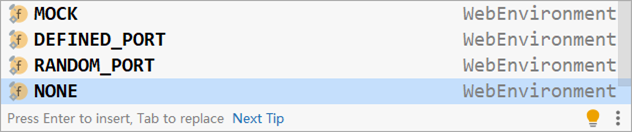
- MOCK:根据当前设置确认是否启动 web 环境,例如使用了 Servlet 的 API 就启动 web 环境,属于适配性的配置
- DEFINED_PORT:使用自定义的端口作为 web 服务器端口
- RANDOM_PORT:使用随机端口作为 web 服务器端口
- NONE:不启动 web 环境
通过上述配置,现在启动测试程序时就可以正常启用 web 环境了,建议大家测试时使用 RANDOM_PORT,避免代码中因为写死设定引发线上功能打包测试时由于端口冲突导致意外现象的出现。就是说你程序中写了用 8080 端口,结果线上环境 8080 端口被占用了,结果你代码中所有写的东西都要改,这就是写死代码的代价。现在你用随机端口就可以测试出来你有没有这种问题的隐患了。
测试环境中的 web 环境已经搭建好了,下面就可以来解决第二个问题了,如何在程序代码中发送 web 请求。
测试类中发送请求
对于测试类中发送请求,其实 java 的 API 就提供对应的功能,只不过平时各位小伙伴接触的比较少,所以较为陌生。springboot 为了便于开发者进行对应的功能开发,对其又进行了包装,简化了开发步骤,具体操作如下:
步骤①:在测试类中开启 web 虚拟调用功能,通过注解 @AutoConfigureMockMvc 实现此功能的开启
1 |
|
步骤②:定义发起虚拟调用的对象 MockMVC,通过自动装配的形式初始化对象
1 |
|
步骤③:创建一个虚拟请求对象,封装请求的路径,并使用 MockMVC 对象发送对应请求
1 |
|
执行测试程序,现在就可以正常的发送 /books 对应的请求了,注意访问路径不要写 http://localhost:8080/books,因为前面的服务器 IP 地址和端口使用的是当前虚拟的 web 环境,无需指定,仅指定请求的具体路径即可。
总结
- 在测试类中测试 web 层接口要保障测试类启动时启动 web 容器,使用 @SpringBootTest 注解的 webEnvironment 属性可以虚拟 web 环境用于测试
- 为测试方法注入 MockMvc 对象,通过 MockMvc 对象可以发送虚拟请求,模拟 web 请求调用过程
思考
目前已经成功的发送了请求,但是还没有起到测试的效果,测试过程必须出现预计值与真实值的比对结果才能确认测试结果是否通过,虚拟请求中能对哪些请求结果进行比对呢?咱们下一节再讲。
web 环境请求结果比对
上一节已经在测试用例中成功的模拟出了 web 环境,并成功的发送了 web 请求,本节就来解决发送请求后如何比对发送结果的问题。其实发完请求得到的信息只有一种,就是响应对象。至于响应对象中包含什么,就可以比对什么。常见的比对内容如下:
-
响应状态匹配
1
2
3
4
5
6
7
8
9
10
11
12
void testStatus( MockMvc mvc) throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
ResultActions action = mvc.perform(builder);
//设定预期值 与真实值进行比较,成功测试通过,失败测试失败
//定义本次调用的预期值
StatusResultMatchers status = MockMvcResultMatchers.status();
//预计本次调用时成功的:状态200
ResultMatcher ok = status.isOk();
//添加预计值到本次调用过程中进行匹配
action.andExpect(ok);
} -
响应体匹配(非 json 数据格式)
1
2
3
4
5
6
7
8
9
10
11
void testBody( MockMvc mvc) throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
ResultActions action = mvc.perform(builder);
//设定预期值 与真实值进行比较,成功测试通过,失败测试失败
//定义本次调用的预期值
ContentResultMatchers content = MockMvcResultMatchers.content();
ResultMatcher result = content.string("springboot2");
//添加预计值到本次调用过程中进行匹配
action.andExpect(result);
} -
响应体匹配(json 数据格式,开发中的主流使用方式)
1
2
3
4
5
6
7
8
9
10
11
void testJson( MockMvc mvc) throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
ResultActions action = mvc.perform(builder);
//设定预期值 与真实值进行比较,成功测试通过,失败测试失败
//定义本次调用的预期值
ContentResultMatchers content = MockMvcResultMatchers.content();
ResultMatcher result = content.json("{\"id\":1,\"name\":\"springboot2\",\"type\":\"springboot\"}");
//添加预计值到本次调用过程中进行匹配
action.andExpect(result);
} -
响应头信息匹配
1
2
3
4
5
6
7
8
9
10
11
void testContentType( MockMvc mvc) throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
ResultActions action = mvc.perform(builder);
//设定预期值 与真实值进行比较,成功测试通过,失败测试失败
//定义本次调用的预期值
HeaderResultMatchers header = MockMvcResultMatchers.header();
ResultMatcher contentType = header.string("Content-Type", "application/json");
//添加预计值到本次调用过程中进行匹配
action.andExpect(contentType);
}
基本上齐了,头信息,正文信息,状态信息都有了,就可以组合出一个完美的响应结果比对结果了。以下范例就是三种信息同时进行匹配校验,也是一个完整的信息匹配过程。
1 |
|
总结
- web 虚拟调用可以对本地虚拟请求的返回响应信息进行比对,分为响应头信息比对、响应体信息比对、响应状态信息比对
# KF-3-4. 数据层测试回滚
当前我们的测试程序可以完美的进行表现层、业务层、数据层接口对应的功能测试了,但是测试用例开发完成后,在打包的阶段由于 test 生命周期属于必须被运行的生命周期,如果跳过会给系统带来极高的安全隐患,所以测试用例必须执行。但是新的问题就呈现了,测试用例如果测试时产生了事务提交就会在测试过程中对数据库数据产生影响,进而产生垃圾数据。这个过程不是我们希望发生的,作为开发者测试用例该运行运行,但是过程中产生的数据不要在我的系统中留痕,这样该如何处理呢?
springboot 早就为开发者想到了这个问题,并且针对此问题给出了最简解决方案,在原始测试用例中添加注解 @Transactional 即可实现当前测试用例的事务不提交。当程序运行后,只要注解 @Transactional 出现的位置存在注解 @SpringBootTest,springboot 就会认为这是一个测试程序,无需提交事务,所以也就可以避免事务的提交。
1 |
|
如果开发者想提交事务,也可以,再添加一个 @RollBack 的注解,设置回滚状态为 false 即可正常提交事务,是不是很方便?springboot 在辅助开发者日常工作这一块展现出了惊人的能力,实在太贴心了。
总结
- 在 springboot 的测试类中通过添加注解 @Transactional 来阻止测试用例提交事务
- 通过注解 @Rollback 控制 springboot 测试类执行结果是否提交事务,需要配合注解 @Transactional 使用
思考
当前测试程序已经近乎完美了,但是由于测试用例中书写的测试数据属于固定数据,往往失去了测试的意义,开发者可以针对测试用例进行针对性开发,这样就有可能出现测试用例不能完美呈现业务逻辑代码是否真实有效的达成业务目标的现象,解决方案其实很容易想,测试用例的数据只要随机产生就可以了,能实现吗?咱们下一节再讲。
# KF-3-5. 测试用例数据设定
对于测试用例的数据固定书写肯定是不合理的,springboot 提供了在配置中使用随机值的机制,确保每次运行程序加载的数据都是随机的。具体如下:
1 | testcase: |
当前配置就可以在每次运行程序时创建一组随机数据,避免每次运行时数据都是固定值的尴尬现象发生,有助于测试功能的进行。数据的加载按照之前加载数据的形式,使用 @ConfigurationProperties 注解即可
1 |
|
对于随机值的产生,还有一些小的限定规则,比如产生的数值性数据可以设置范围等,具体如下:

- ${random.int} 表示随机整数
- ${random.int (10)} 表示 10 以内的随机数
- ${random.int (10,20)} 表示 10 到 20 的随机数
- 其中 () 可以是任意字符,例如 [],!! 均可
总结
- 使用随机数据可以替换测试用例中书写的固定数据,提高测试用例中的测试数据有效性
# KF-4. 数据层解决方案
开发实用篇前三章基本上是开胃菜,从第四章开始,开发实用篇进入到了噩梦难度了,从这里开始,不再是单纯的在 springboot 内部搞事情了,要涉及到很多相关知识。本章节主要内容都是和数据存储与读取相关,前期学习的知识与数据层有关的技术基本上都围绕在数据库这个层面上,所以本章要讲的第一个大的分支就是 SQL 解决方案相关的内容,除此之外,数据的来源还可以是非 SQL 技术相关的数据操作,因此第二部分围绕着 NOSQL 解决方案讲解。至于什么是 NOSQL 解决方案,讲到了再说吧。下面就从 SQL 解决方案说起。
# KF-4-1.SQL
回忆一下之前做 SSMP 整合的时候数据层解决方案涉及到了哪些技术?MySQL 数据库与 MyBatisPlus 框架,后面又学了 Druid 数据源的配置,所以现在数据层解决方案可以说是 Mysql+Druid+MyBatisPlus。而三个技术分别对应了数据层操作的三个层面:
- 数据源技术:Druid
- 持久化技术:MyBatisPlus
- 数据库技术:MySQL
下面的研究就分为三个层面进行研究,对应上面列出的三个方面,咱们就从第一个数据源技术开始说起。
# 数据源技术
目前我们使用的数据源技术是 Druid,运行时可以在日志中看到对应的数据源初始化信息,具体如下:
1 | INFO 28600 --- [ main] c.a.d.s.b.a.DruidDataSourceAutoConfigure : Init DruidDataSource |
如果不使用 Druid 数据源,程序运行后是什么样子呢?是独立的数据库连接对象还是有其他的连接池技术支持呢?将 Druid 技术对应的 starter 去掉再次运行程序可以在日志中找到如下初始化信息:
1 | INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... |
虽然没有 DruidDataSource 相关的信息了,但是我们发现日志中有 HikariDataSource 这个信息,就算不懂这是个什么技术,看名字也能看出来,以 DataSource 结尾的名称,这一定是一个数据源技术。我们又没有手工添加这个技术,这个技术哪里来的呢?这就是这一节要讲的知识,springboot 内嵌数据源。
数据层技术是每一个企业级应用程序都会用到的,而其中必定会进行数据库连接的管理。springboot 根据开发者的习惯出发,开发者提供了数据源技术,就用你提供的,开发者没有提供,那总不能手工管理一个一个的数据库连接对象啊,怎么办?我给你一个默认的就好了,这样省心又省事,大家都方便。
springboot 提供了 3 款内嵌数据源技术,分别如下:
- HikariCP
- Tomcat 提供 DataSource
- Commons DBCP
第一种,HikartCP,这是 springboot 官方推荐的数据源技术,作为默认内置数据源使用。啥意思?你不配置数据源,那就用这个。
第二种,Tomcat 提供的 DataSource,如果不想用 HikartCP,并且使用 tomcat 作为 web 服务器进行 web 程序的开发,使用这个。为什么是 Tomcat,不是其他 web 服务器呢?因为 web 技术导入 starter 后,默认使用内嵌 tomcat,既然都是默认使用的技术了,那就一用到底,数据源也用它的。有人就提出怎么才能不使用 HikartCP 用 tomcat 提供的默认数据源对象呢?把 HikartCP 技术的坐标排除掉就 OK 了。
第三种,DBCP,这个使用的条件就更苛刻了,既不使用 HikartCP 也不使用 tomcat 的 DataSource 时,默认给你用这个。
springboot 这心操的,也是稀碎啊,就怕你自己管不好连接对象,给你一顿推荐,真是开发界的最强辅助。既然都给你奶上了,那就受用吧,怎么配置使用这些东西呢?之前我们配置 druid 时使用 druid 的 starter 对应的配置如下:
1 | spring: |
换成是默认的数据源 HikariCP 后,直接吧 druid 删掉就行了,如下:
1 | spring: |
当然,也可以写上是对 hikari 做的配置,但是 url 地址要单独配置,如下:
1 | spring: |
这就是配置 hikari 数据源的方式。如果想对 hikari 做进一步的配置,可以继续配置其独立的属性。例如:
1 | spring: |
如果不想使用 hikari 数据源,使用 tomcat 的数据源或者 DBCP 配置格式也是一样的。学习到这里,以后我们做数据层时,数据源对象的选择就不再是单一的使用 druid 数据源技术了,可以根据需要自行选择。
总结
- springboot 技术提供了 3 种内置的数据源技术,分别是 Hikari、tomcat 内置数据源、DBCP
# 持久化技术
说完数据源解决方案,再来说一下持久化解决方案。springboot 充分发挥其最强辅助的特征,给开发者提供了一套现成的数据层技术,叫做 JdbcTemplate。其实这个技术不能说是 springboot 提供的,因为不使用 springboot 技术,一样能使用它,谁提供的呢?spring 技术提供的,所以在 springboot 技术范畴中,这个技术也是存在的,毕竟 springboot 技术是加速 spring 程序开发而创建的。
这个技术其实就是回归到 jdbc 最原始的编程形式来进行数据层的开发,下面直接上操作步骤:
步骤①:导入 jdbc 对应的坐标,记得是 starter
1 | <dependency> |
步骤②:自动装配 JdbcTemplate 对象
1 |
|
步骤③:使用 JdbcTemplate 实现查询操作(非实体类封装数据的查询操作)
1 |
|
步骤④:使用 JdbcTemplate 实现查询操作(实体类封装数据的查询操作)
1 |
|
步骤⑤:使用 JdbcTemplate 实现增删改操作
1 |
|
如果想对 JdbcTemplate 对象进行相关配置,可以在 yml 文件中进行设定,具体如下:
1 | spring: |
总结
- SpringBoot 内置 JdbcTemplate 持久化解决方案
- 使用 JdbcTemplate 需要导入 spring-boot-starter-jdbc 的坐标
# 数据库技术
截止到目前,springboot 给开发者提供了内置的数据源解决方案和持久化解决方案,在数据层解决方案三件套中还剩下一个数据库,莫非 springboot 也提供有内置的解决方案?还真有,还不是一个,三个,这一节就来说说内置的数据库解决方案。
springboot 提供了 3 款内置的数据库,分别是
- H2
- HSQL
- Derby
以上三款数据库除了可以独立安装之外,还可以像是 tomcat 服务器一样,采用内嵌的形式运行在 spirngboot 容器中。内嵌在容器中运行,那必须是 java 对象啊,对,这三款数据库底层都是使用 java 语言开发的。
我们一直使用 MySQL 数据库就挺好的,为什么有需求用这个呢?原因就在于这三个数据库都可以采用内嵌容器的形式运行,在应用程序运行后,如果我们进行测试工作,此时测试的数据无需存储在磁盘上,但是又要测试使用,内嵌数据库就方便了,运行在内存中,该测试测试,该运行运行,等服务器关闭后,一切烟消云散,多好,省得你维护外部数据库了。这也是内嵌数据库的最大优点,方便进行功能测试。
下面以 H2 数据库为例讲解如何使用这些内嵌数据库,操作步骤也非常简单,简单才好用嘛
步骤①:导入 H2 数据库对应的坐标,一共 2 个
1 | <dependency> |
步骤②:将工程设置为 web 工程,启动工程时启动 H2 数据库
1 | <dependency> |
步骤③:通过配置开启 H2 数据库控制台访问程序,也可以使用其他的数据库连接软件操作
1 | spring: |
web 端访问路径 /h2,访问密码 123456,如果访问失败,先配置下列数据源,启动程序运行后再次访问 /h2 路径就可以正常访问了
1 | datasource: |
步骤④:使用 JdbcTemplate 或 MyBatisPlus 技术操作数据库
(略)
其实我们只是换了一个数据库而已,其他的东西都不受影响。一个重要提醒,别忘了,上线时,把内存级数据库关闭,采用 MySQL 数据库作为数据持久化方案,关闭方式就是设置 enabled 属性为 false 即可。
总结
- H2 内嵌式数据库启动方式,添加坐标,添加配置
- H2 数据库线上运行时请务必关闭
到这里 SQL 相关的数据层解决方案就讲完了,现在的可选技术就丰富的多了。
- 数据源技术:Druid、Hikari、tomcat DataSource、DBCP
- 持久化技术:MyBatisPlus、MyBatis、JdbcTemplate
- 数据库技术:MySQL、H2、HSQL、Derby
现在开发程序时就可以在以上技术中任选一种组织成一套数据库解决方案了。
# KF-4-2.NoSQL
SQL 数据层解决方案说完了,下面来说收 NoSQL 数据层解决方案。这个 NoSQL 是什么意思呢?从字面来看,No 表示否定,NoSQL 就是非关系型数据库解决方案,意思就是数据该存存该取取,只是这些数据不放在关系型数据库中了,那放在哪里?自然是一些能够存储数据的其他相关技术中了,比如 Redis 等。本节讲解的内容就是 springboot 如何整合这些技术,在 springboot 官方文档中提供了 10 种相关技术的整合方案,我们将讲解国内市场上最流行的几款 NoSQL 数据库整合方案,分别是 Redis、MongoDB、ES。
因为每个小伙伴学习这门课程的时候起点不同,为了便于各位学习者更好的学习,每种技术在讲解整合前都会先讲一下安装和基本使用,然后再讲整合。如果对某个技术比较熟悉的小伙伴可以直接跳过安装的学习过程,直接看整合方案即可。此外上述这些技术最佳使用方案都是在 Linux 服务器上部署,但是考虑到各位小伙伴的学习起点差异过大,所以下面的课程都是以 Windows 平台作为安装基础讲解,如果想看 Linux 版软件安装,可以再找到对应技术的学习文档查阅学习。
# SpringBoot 整合 Redis
Redis 是一款采用 key-value 数据存储格式的内存级 NoSQL 数据库,重点关注数据存储格式,是 key-value 格式,也就是键值对的存储形式。与 MySQL 数据库不同,MySQL 数据库有表、有字段、有记录,Redis 没有这些东西,就是一个名称对应一个值,并且数据以存储在内存中使用为主。什么叫以存储在内存中为主?其实 Redis 有它的数据持久化方案,分别是 RDB 和 AOF,但是 Redis 自身并不是为了数据持久化而生的,主要是在内存中保存数据,加速数据访问的,所以说是一款内存级数据库。
Redis 支持多种数据存储格式,比如可以直接存字符串,也可以存一个 map 集合,list 集合,后面会涉及到一些不同格式的数据操作,这个需要先学习一下才能进行整合,所以在基本操作中会介绍一些相关操作。下面就先安装,再操作,最后说整合
# 安装
windows 版安装包下载地址:https://github.com/tporadowski/redis/releases
下载的安装包有两种形式,一种是一键安装的 msi 文件,还有一种是解压缩就能使用的 zip 文件,哪种形式都行,这里就不介绍安装过程了,本课程采用的是 msi 一键安装的 msi 文件进行安装的。
啥是 msi,其实就是一个文件安装包,不仅安装软件,还帮你把安装软件时需要的功能关联在一起,打包操作。比如如安装序列、创建和设置安装路径、设置系统依赖项、默认设定安装选项和控制安装过程的属性。说简单点就是一站式服务,安装过程一条龙操作一气呵成,就是为小白用户提供的软件安装程序。
安装完毕后会得到如下文件,其中有两个文件对应两个命令,是启动 Redis 的核心命令,需要再 CMD 命令行模式执行。
启动服务器
1 | redis-server.exe redis.windows.conf |
初学者无需调整服务器对外服务端口,默认 6379。
启动客户端
1 | redis-cli.exe |
如果启动 redis 服务器失败,可以先启动客户端,然后执行 shutdown 操作后退出,此时 redis 服务器就可以正常执行了。
# 基本操作
服务器启动后,使用客户端就可以连接服务器,类似于启动完 MySQL 数据库,然后启动 SQL 命令行操作数据库。
放置一个字符串数据到 redis 中,先为数据定义一个名称,比如 name,age 等,然后使用命令 set 设置数据到 redis 服务器中即可
1 | set name itheima |
从 redis 中取出已经放入的数据,根据名称取,就可以得到对应数据。如果没有对应数据就会得到 (nil)
1 | get name |
以上使用的数据存储是一个名称对应一个值,如果要维护的数据过多,可以使用别的数据存储结构。例如 hash,它是一种一个名称下可以存储多个数据的存储模型,并且每个数据也可以有自己的二级存储名称。向 hash 结构中存储数据格式如下:
1 | hset a a1 aa1 #对外key名称是a,在名称为a的存储模型中,a1这个key中保存了数据aa1 |
获取 hash 结构中的数据命令如下
1 | hget a a1 #得到aa1 |
有关 redis 的基础操作就普及到这里,需要全面掌握 redis 技术,请参看相关教程学习。
# 整合
在进行整合之前先梳理一下整合的思想,springboot 整合任何技术其实就是在 springboot 中使用对应技术的 API。如果两个技术没有交集,就不存在整合的概念了。所谓整合其实就是使用 springboot 技术去管理其他技术,几个问题是躲不掉的。
第一,需要先导入对应技术的坐标,而整合之后,这些坐标都有了一些变化
第二,任何技术通常都会有一些相关的设置信息,整合之后,这些信息如何写,写在哪是一个问题
第三,没有整合之前操作如果是模式 A 的话,整合之后如果没有给开发者带来一些便捷操作,那整合将毫无意义,所以整合后操作肯定要简化一些,那对应的操作方式自然也有所不同
按照上面的三个问题去思考 springboot 整合所有技术是一种通用思想,在整合的过程中会逐步摸索出整合的套路,而且适用性非常强,经过若干种技术的整合后基本上可以总结出一套固定思维。
下面就开始 springboot 整合 redis,操作步骤如下:
步骤①:导入 springboot 整合 redis 的 starter 坐标
1 | <dependency> |
上述坐标可以在创建模块的时候通过勾选的形式进行选择,归属 NoSQL 分类中
步骤②:进行基础配置
1 | spring: |
操作 redis,最基本的信息就是操作哪一台 redis 服务器,所以服务器地址属于基础配置信息,不可缺少。但是即便你不配置,目前也是可以用的。因为以上两组信息都有默认配置,刚好就是上述配置值。
步骤③:使用 springboot 整合 redis 的专用客户端接口操作,此处使用的是 RedisTemplate
1 |
|
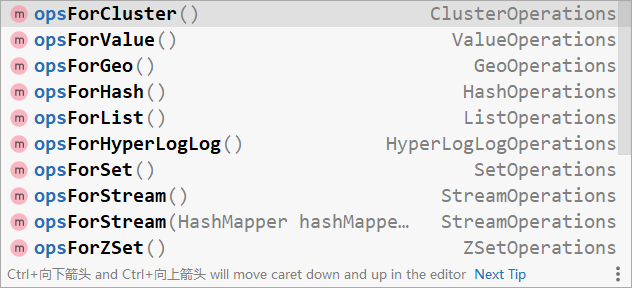
在操作 redis 时,需要先确认操作何种数据,根据数据种类得到操作接口。例如使用 opsForValue () 获取 string 类型的数据操作接口,使用 opsForHash () 获取 hash 类型的数据操作接口,剩下的就是调用对应 api 操作了。各种类型的数据操作接口如下:
总结
- springboot 整合 redis 步骤
- 导入 springboot 整合 redis 的 starter 坐标
- 进行基础配置
- 使用 springboot 整合 redis 的专用客户端接口 RedisTemplate 操作
StringRedisTemplate
由于 redis 内部不提供 java 对象的存储格式,因此当操作的数据以对象的形式存在时,会进行转码,转换成字符串格式后进行操作。为了方便开发者使用基于字符串为数据的操作,springboot 整合 redis 时提供了专用的 API 接口 StringRedisTemplate,你可以理解为这是 RedisTemplate 的一种指定数据泛型的操作 API。
1 |
|
redis 客户端选择
springboot整合redis技术提供了多种客户端兼容模式,默认提供的是lettucs客户端技术,也可以根据需要切换成指定客户端技术,例如jedis客户端技术,切换成jedis客户端技术操作步骤如下:
步骤①:导入 jedis 坐标
1 | <dependency> |
jedis 坐标受 springboot 管理,无需提供版本号
步骤②:配置客户端技术类型,设置为 jedis
1 | spring: |
步骤③:根据需要设置对应的配置
1 | spring: |
lettcus 与 jedis 区别
- jedis 连接 Redis 服务器是直连模式,当多线程模式下使用 jedis 会存在线程安全问题,解决方案可以通过配置连接池使每个连接专用,这样整体性能就大受影响
- lettcus 基于 Netty 框架进行与 Redis 服务器连接,底层设计中采用 StatefulRedisConnection。 StatefulRedisConnection 自身是线程安全的,可以保障并发访问安全问题,所以一个连接可以被多线程复用。当然 lettcus 也支持多连接实例一起工作
总结
- springboot 整合 redis 提供了 StringRedisTemplate 对象,以字符串的数据格式操作 redis
- 如果需要切换 redis 客户端实现技术,可以通过配置的形式进行
# SpringBoot 整合 MongoDB
使用 Redis 技术可以有效的提高数据访问速度,但是由于 Redis 的数据格式单一性,无法操作结构化数据,当操作对象型的数据时,Redis 就显得捉襟见肘。在保障访问速度的情况下,如果想操作结构化数据,看来 Redis 无法满足要求了,此时需要使用全新的数据存储结束来解决此问题,本节讲解 springboot 如何整合 MongoDB 技术。
MongoDB 是一个开源、高性能、无模式的文档型数据库,它是 NoSQL 数据库产品中的一种,是最像关系型数据库的非关系型数据库。
上述描述中几个词,其中对于我们最陌生的词是无模式的。什么叫无模式呢?简单说就是作为一款数据库,没有固定的数据存储结构,第一条数据可能有 A、B、C 一共 3 个字段,第二条数据可能有 D、E、F 也是 3 个字段,第三条数据可能是 A、C、E3 个字段,也就是说数据的结构不固定,这就是无模式。有人会说这有什么用啊?灵活,随时变更,不受约束。基于上述特点,MongoDB 的应用面也会产生一些变化。以下列出了一些可以使用 MongoDB 作为数据存储的场景,但是并不是必须使用 MongoDB 的场景:
- 淘宝用户数据
- 存储位置:数据库
- 特征:永久性存储,修改频度极低
- 游戏装备数据、游戏道具数据
- 存储位置:数据库、Mongodb
- 特征:永久性存储与临时存储相结合、修改频度较高
- 直播数据、打赏数据、粉丝数据
- 存储位置:数据库、Mongodb
- 特征:永久性存储与临时存储相结合,修改频度极高
- 物联网数据
- 存储位置:Mongodb
- 特征:临时存储,修改频度飞速
快速了解一下 MongoDB,下面直接开始我们的学习,老规矩,先安装,再操作,最后说整合
# 安装
windows 版安装包下载地址:https://www.mongodb.com/try/download
下载的安装包也有两种形式,一种是一键安装的 msi 文件,还有一种是解压缩就能使用的 zip 文件,哪种形式都行,本课程采用解压缩 zip 文件进行安装。
解压缩完毕后会得到如下文件,其中 bin 目录包含了所有 mongodb 的可执行命令
mongodb 在运行时需要指定一个数据存储的目录,所以创建一个数据存储目录,通常放置在安装目录中,此处创建 data 的目录用来存储数据,具体如下
如果在安装的过程中出现了如下警告信息,就是告诉你,你当前的操作系统缺少了一些系统文件,这个不用担心。
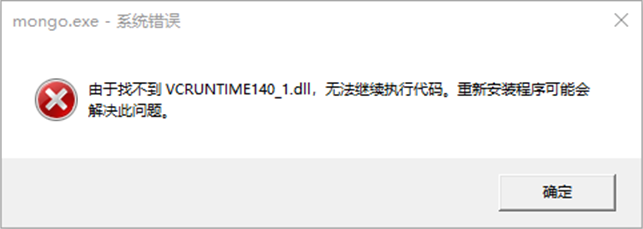
根据下列方案即可解决,在浏览器中搜索提示缺少的名称对应的文件,并下载,将下载的文件拷贝到 windows 安装目录的 system32 目录下,然后在命令行中执行 regsvr32 命令注册此文件。根据下载的文件名不同,执行命令前更改对应名称。
1 | regsvr32 vcruntime140_1.dll |
启动服务器
1 | mongod --dbpath=..\data\db |
启动服务器时需要指定数据存储位置,通过参数–dbpath 进行设置,可以根据需要自行设置数据存储路径。默认服务端口 27017。
启动客户端
1 | mongo --host=127.0.0.1 --port=27017 |
# 基本操作
MongoDB 虽然是一款数据库,但是它的操作并不是使用 SQL 语句进行的,因此操作方式各位小伙伴可能比较陌生,好在有一些类似于 Navicat 的数据库客户端软件,能够便捷的操作 MongoDB,先安装一个客户端,再来操作 MongoDB。
同类型的软件较多,本次安装的软件时 Robo3t,Robot3t 是一款绿色软件,无需安装,解压缩即可。解压缩完毕后进入安装目录双击 robot3t.exe 即可使用。
打开软件首先要连接 MongoDB 服务器,选择【File】菜单,选择【Connect…】
进入连接管理界面后,选择左上角的【Create】链接,创建新的连接设置
如果输入设置值即可连接(默认不修改即可连接本机 27017 端口)
连接成功后在命令输入区域输入命令即可操作 MongoDB。
创建数据库:在左侧菜单中使用右键创建,输入数据库名称即可
创建集合:在 Collections 上使用右键创建,输入集合名称即可,集合等同于数据库中的表的作用
新增文档:(文档是一种类似 json 格式的数据,初学者可以先把数据理解为就是 json 数据)
1 | db.集合名称.insert/save/insertOne(文档) |
删除文档:
1 | db.集合名称.remove(条件) |
修改文档:
1 | db.集合名称.update(条件,{操作种类:{文档}}) |
查询文档:
1 | 基础查询 |
有关 MongoDB 的基础操作就普及到这里,需要全面掌握 MongoDB 技术,请参看相关教程学习。
# 整合
使用 springboot 整合 MongDB 该如何进行呢?其实 springboot 为什么使用的开发者这么多,就是因为他的套路几乎完全一样。导入坐标,做配置,使用 API 接口操作。整合 Redis 如此,整合 MongoDB 同样如此。
第一,先导入对应技术的整合 starter 坐标
第二,配置必要信息
第三,使用提供的 API 操作即可
下面就开始 springboot 整合 MongoDB,操作步骤如下:
步骤①:导入 springboot 整合 MongoDB 的 starter 坐标
1 | <dependency> |
上述坐标也可以在创建模块的时候通过勾选的形式进行选择,同样归属 NoSQL 分类中
步骤②:进行基础配置
1 | spring: |
操作 MongoDB 需要的配置与操作 redis 一样,最基本的信息都是操作哪一台服务器,区别就是连接的服务器 IP 地址和端口不同,书写格式不同而已。
步骤③:使用 springboot 整合 MongoDB 的专用客户端接口 MongoTemplate 来进行操作
1 |
|
整合工作到这里就做完了,感觉既熟悉也陌生。熟悉的是这个套路,三板斧,就这三招,导坐标做配置用 API 操作,陌生的是这个技术,里面具体的操作 API 可能会不熟悉,有关 springboot 整合 MongoDB 我们就讲到这里。有兴趣可以继续学习 MongoDB 的操作,然后再来这里通过编程的形式操作 MongoDB。
总结
- springboot 整合 MongoDB 步骤
- 导入 springboot 整合 MongoDB 的 starter 坐标
- 进行基础配置
- 使用 springboot 整合 MongoDB 的专用客户端接口 MongoTemplate 操作
# SpringBoot 整合 ES
NoSQL 解决方案已经讲完了两种技术的整合了,Redis 可以使用内存加载数据并实现数据快速访问,MongoDB 可以在内存中存储类似对象的数据并实现数据的快速访问,在企业级开发中对于速度的追求是永无止境的。下面要讲的内容也是一款 NoSQL 解决方案,只不过他的作用不是为了直接加速数据的读写,而是加速数据的查询的,叫做 ES 技术。
ES(Elasticsearch)是一个分布式全文搜索引擎,重点是全文搜索。
那什么是全文搜索呢?比如用户要买一本书,以 Java 为关键字进行搜索,不管是书名中还是书的介绍中,甚至是书的作者名字,只要包含 java 就作为查询结果返回给用户查看,上述过程就使用了全文搜索技术。搜索的条件不再是仅用于对某一个字段进行比对,而是在一条数据中使用搜索条件去比对更多的字段,只要能匹配上就列入查询结果,这就是全文搜索的目的。而 ES 技术就是一种可以实现上述效果的技术。
要实现全文搜索的效果,不可能使用数据库中 like 操作去进行比对,这种效率太低了。ES 设计了一种全新的思想,来实现全文搜索。具体操作过程如下:
-
将被查询的字段的数据全部文本信息进行查分,分成若干个词
- 例如 “中华人民共和国” 就会被拆分成三个词,分别是 “中华”、“人民”、“共和国”,此过程有专业术语叫做分词。分词的策略不同,分出的效果不一样,不同的分词策略称为分词器。
-
将分词得到的结果存储起来,对应每条数据的 id
-
例如 id 为 1 的数据中名称这一项的值是 “中华人民共和国”,那么分词结束后,就会出现 “中华” 对应 id 为 1,“人民” 对应 id 为 1,“共和国” 对应 id 为 1
-
例如 id 为 2 的数据中名称这一项的值是 “人民代表大会 “,那么分词结束后,就会出现 “人民” 对应 id 为 2,“代表” 对应 id 为 2,“大会” 对应 id 为 2
-
此时就会出现如下对应结果,按照上述形式可以对所有文档进行分词。需要注意分词的过程不是仅对一个字段进行,而是对每一个参与查询的字段都执行,最终结果汇总到一个表格中
分词结果关键字 对应 id 中华 1 人民 1,2 共和国 1 代表 2 大会 2
-
-
当进行查询时,如果输入 “人民” 作为查询条件,可以通过上述表格数据进行比对,得到 id 值 1,2,然后根据 id 值就可以得到查询的结果数据了。
上述过程中分词结果关键字内容每一个都不相同,作用有点类似于数据库中的索引,是用来加速数据查询的。但是数据库中的索引是对某一个字段进行添加索引,而这里的分词结果关键字不是一个完整的字段值,只是一个字段中的其中的一部分内容。并且索引使用时是根据索引内容查找整条数据,全文搜索中的分词结果关键字查询后得到的并不是整条的数据,而是数据的 id,要想获得具体数据还要再次查询,因此这里为这种分词结果关键字起了一个全新的名称,叫做倒排索引。
通过上述内容的学习,发现使用 ES 其实准备工作还是挺多的,必须先建立文档的倒排索引,然后才能继续使用。快速了解一下 ES 的工作原理,下面直接开始我们的学习,老规矩,先安装,再操作,最后说整合。
# 安装
windows 版安装包下载地址:https://www.elastic.co/cn/downloads/elasticsearch
下载的安装包是解压缩就能使用的 zip 文件,解压缩完毕后会得到如下文件
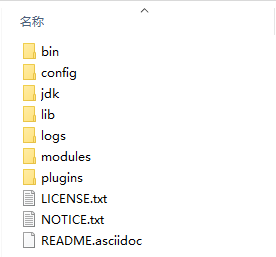
- bin 目录:包含所有的可执行命令
- config 目录:包含 ES 服务器使用的配置文件
- jdk 目录:此目录中包含了一个完整的 jdk 工具包,版本 17,当 ES 升级时,使用最新版本的 jdk 确保不会出现版本支持性不足的问题
- lib 目录:包含 ES 运行的依赖 jar 文件
- logs 目录:包含 ES 运行后产生的所有日志文件
- modules 目录:包含 ES 软件中所有的功能模块,也是一个一个的 jar 包。和 jar 目录不同,jar 目录是 ES 运行期间依赖的 jar 包,modules 是 ES 软件自己的功能 jar 包
- plugins 目录:包含 ES 软件安装的插件,默认为空
启动服务器
1 | elasticsearch.bat |
双击 elasticsearch.bat 文件即可启动 ES 服务器,默认服务端口 9200。通过浏览器访问 http://localhost:9200 看到如下信息视为 ES 服务器正常启动
1 | { |
# 基本操作
ES 中保存有我们要查询的数据,只不过格式和数据库存储数据格式不同而已。在 ES 中我们要先创建倒排索引,这个索引的功能又点类似于数据库的表,然后将数据添加到倒排索引中,添加的数据称为文档。所以要进行 ES 的操作要先创建索引,再添加文档,这样才能进行后续的查询操作。
要操作 ES 可以通过 Rest 风格的请求来进行,也就是说发送一个请求就可以执行一个操作。比如新建索引,删除索引这些操作都可以使用发送请求的形式来进行。
-
创建索引,books 是索引名称,下同
1
PUT请求 http://localhost:9200/books
发送请求后,看到如下信息即索引创建成功
1
2
3
4
5{
"acknowledged": true,
"shards_acknowledged": true,
"index": "books"
}重复创建已经存在的索引会出现错误信息,reason 属性中描述错误原因
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists",
"index_uuid": "VgC_XMVAQmedaiBNSgO2-w",
"index": "books"
}
],
"type": "resource_already_exists_exception",
"reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists", # books索引已经存在
"index_uuid": "VgC_XMVAQmedaiBNSgO2-w",
"index": "book"
},
"status": 400
} -
查询索引
1
GET请求 http://localhost:9200/books
查询索引得到索引相关信息,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25{
"book": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1645768584849",
"number_of_replicas": "1",
"uuid": "VgC_XMVAQmedaiBNSgO2-w",
"version": {
"created": "7160299"
}
}
}
}
}如果查询了不存在的索引,会返回错误信息,例如查询名称为 book 的索引后信息如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index [book]",
"resource.type": "index_or_alias",
"resource.id": "book",
"index_uuid": "_na_",
"index": "book"
}
],
"type": "index_not_found_exception",
"reason": "no such index [book]", # 没有book索引
"resource.type": "index_or_alias",
"resource.id": "book",
"index_uuid": "_na_",
"index": "book"
},
"status": 404
} -
删除索引
1
DELETE请求 http://localhost:9200/books
删除所有后,给出删除结果
1
2
3{
"acknowledged": true
}如果重复删除,会给出错误信息,同样在 reason 属性中描述具体的错误原因
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index [books]",
"resource.type": "index_or_alias",
"resource.id": "book",
"index_uuid": "_na_",
"index": "book"
}
],
"type": "index_not_found_exception",
"reason": "no such index [books]", # 没有books索引
"resource.type": "index_or_alias",
"resource.id": "book",
"index_uuid": "_na_",
"index": "book"
},
"status": 404
} -
创建索引并指定分词器
前面创建的索引是未指定分词器的,可以在创建索引时添加请求参数,设置分词器。目前国内较为流行的分词器是 IK 分词器,使用前先在下对应的分词器,然后使用。IK 分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
分词器下载后解压到 ES 安装目录的 plugins 目录中即可,安装分词器后需要重新启动 ES 服务器。使用 IK 分词器创建索引格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29PUT请求 http://localhost:9200/books
请求参数如下(注意是json格式的参数)
{
"mappings":{ #定义mappings属性,替换创建索引时对应的mappings属性
"properties":{ #定义索引中包含的属性设置
"id":{ #设置索引中包含id属性
"type":"keyword" #当前属性可以被直接搜索
},
"name":{ #设置索引中包含name属性
"type":"text", #当前属性是文本信息,参与分词
"analyzer":"ik_max_word", #使用IK分词器进行分词
"copy_to":"all" #分词结果拷贝到all属性中
},
"type":{
"type":"keyword"
},
"description":{
"type":"text",
"analyzer":"ik_max_word",
"copy_to":"all"
},
"all":{ #定义属性,用来描述多个字段的分词结果集合,当前属性可以参与查询
"type":"text",
"analyzer":"ik_max_word"
}
}
}
} 创建完毕后返回结果和不使用分词器创建索引的结果是一样的,此时可以通过查看索引信息观察到添加的请求参数 mappings 已经进入到了索引属性中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52{
"books": {
"aliases": {},
"mappings": { #mappings属性已经被替换
"properties": {
"all": {
"type": "text",
"analyzer": "ik_max_word"
},
"description": {
"type": "text",
"copy_to": [
"all"
],
"analyzer": "ik_max_word"
},
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"copy_to": [
"all"
],
"analyzer": "ik_max_word"
},
"type": {
"type": "keyword"
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1645769809521",
"number_of_replicas": "1",
"uuid": "DohYKvr_SZO4KRGmbZYmTQ",
"version": {
"created": "7160299"
}
}
}
}
}
目前我们已经有了索引了,但是索引中还没有数据,所以要先添加数据,ES 中称数据为文档,下面进行文档操作。
-
添加文档,有三种方式
1
2
3
4
5
6
7
8
9
10POST请求 http://localhost:9200/books/_doc #使用系统生成id
POST请求 http://localhost:9200/books/_create/1 #使用指定id
POST请求 http://localhost:9200/books/_doc/1 #使用指定id,不存在创建,存在更新(版本递增)
文档通过请求参数传递,数据格式json
{
"name":"springboot",
"type":"springboot",
"description":"springboot"
} -
查询文档
1
2GET请求 http://localhost:9200/books/_doc/1 #查询单个文档
GET请求 http://localhost:9200/books/_search #查询全部文档 -
条件查询
1
GET请求 http://localhost:9200/books/_search?q=name:springboot # q=查询属性名:查询属性值
-
删除文档
1
DELETE请求 http://localhost:9200/books/_doc/1
-
修改文档(全量更新)
1
2
3
4
5
6
7
8PUT请求 http://localhost:9200/books/_doc/1
文档通过请求参数传递,数据格式json
{
"name":"springboot",
"type":"springboot",
"description":"springboot"
} -
修改文档(部分更新)
1
2
3
4
5
6
7
8POST请求 http://localhost:9200/books/_update/1
文档通过请求参数传递,数据格式json
{
"doc":{ #部分更新并不是对原始文档进行更新,而是对原始文档对象中的doc属性中的指定属性更新
"name":"springboot" #仅更新提供的属性值,未提供的属性值不参与更新操作
}
}
# 整合
使用 springboot 整合 ES 该如何进行呢?老规矩,导入坐标,做配置,使用 API 接口操作。整合 Redis 如此,整合 MongoDB 如此,整合 ES 依然如此。太没有新意了,其实不是没有新意,这就是 springboot 的强大之处,所有东西都做成相同规则,对开发者来说非常友好。
下面就开始 springboot 整合 ES,操作步骤如下:
步骤①:导入 springboot 整合 ES 的 starter 坐标
1 | <dependency> |
步骤②:进行基础配置
1 | spring: |
配置 ES 服务器地址,端口 9200
步骤③:使用 springboot 整合 ES 的专用客户端接口 ElasticsearchRestTemplate 来进行操作
1 |
|
上述操作形式是 ES 早期的操作方式,使用的客户端被称为 Low Level Client,这种客户端操作方式性能方面略显不足,于是 ES 开发了全新的客户端操作方式,称为 High Level Client。高级别客户端与 ES 版本同步更新,但是 springboot 最初整合 ES 的时候使用的是低级别客户端,所以企业开发需要更换成高级别的客户端模式。
下面使用高级别客户端方式进行 springboot 整合 ES,操作步骤如下:
步骤①:导入 springboot 整合 ES 高级别客户端的坐标,此种形式目前没有对应的 starter
1 | <dependency> |
步骤②:使用编程的形式设置连接的 ES 服务器,并获取客户端对象
1 |
|
配置 ES 服务器地址与端口 9200,记得客户端使用完毕需要手工关闭。由于当前客户端是手工维护的,因此不能通过自动装配的形式加载对象。
步骤③:使用客户端对象操作 ES,例如创建索引
1 |
|
高级别客户端操作是通过发送请求的方式完成所有操作的,ES 针对各种不同的操作,设定了各式各样的请求对象,上例中创建索引的对象是 CreateIndexRequest,其他操作也会有自己专用的 Request 对象。
当前操作我们发现,无论进行 ES 何种操作,第一步永远是获取 RestHighLevelClient 对象,最后一步永远是关闭该对象的连接。在测试中可以使用测试类的特性去帮助开发者一次性的完成上述操作,但是在业务书写时,还需要自行管理。将上述代码格式转换成使用测试类的初始化方法和销毁方法进行客户端对象的维护。
1 |
|
现在的书写简化了很多,也更合理。下面使用上述模式将所有的 ES 操作执行一遍,测试结果
创建索引(IK 分词器):
1 |
|
IK 分词器是通过请求参数的形式进行设置的,设置请求参数使用 request 对象中的 source 方法进行设置,至于参数是什么,取决于你的操作种类。当请求中需要参数时,均可使用当前形式进行参数设置。
添加文档:
1 |
|
添加文档使用的请求对象是 IndexRequest,与创建索引使用的请求对象不同。
批量添加文档:
1 |
|
批量做时,先创建一个 BulkRequest 的对象,可以将该对象理解为是一个保存 request 对象的容器,将所有的请求都初始化好后,添加到 BulkRequest 对象中,再使用 BulkRequest 对象的 bulk 方法,一次性执行完毕。
按 id 查询文档:
1 |
|
根据 id 查询文档使用的请求对象是 GetRequest。
按条件查询文档:
1 |
|
按条件查询文档使用的请求对象是 SearchRequest,查询时调用 SearchRequest 对象的 termQuery 方法,需要给出查询属性名,此处支持使用合并字段,也就是前面定义索引属性时添加的 all 属性。
springboot 整合 ES 的操作到这里就说完了,与前期进行 springboot 整合 redis 和 mongodb 的差别还是蛮大的,主要原始就是我们没有使用 springboot 整合 ES 的客户端对象。至于操作,由于 ES 操作种类过多,所以显得操作略微有点复杂。有关 springboot 整合 ES 就先学习到这里吧。
总结
- springboot 整合 ES 步骤
- 导入 springboot 整合 ES 的 High Level Client 坐标
- 手工管理客户端对象,包括初始化和关闭操作
- 使用 High Level Client 根据操作的种类不同,选择不同的 Request 对象完成对应操作
# KF-5. 整合第三方技术
通过第四章的学习,我们领略到了 springboot 在整合第三方技术时强大的一致性,在第五章中我们要使用 springboot 继续整合各种各样的第三方技术,通过本章的学习,可以将之前学习的 springboot 整合第三方技术的思想贯彻到底,还是那三板斧。导坐标、做配置、调 API。
springboot 能够整合的技术实在是太多了,可以说是万物皆可整。本章将从企业级开发中常用的一些技术作为出发点,对各种各样的技术进行整合。
# KF-5-1. 缓存
企业级应用主要作用是信息处理,当需要读取数据时,由于受限于数据库的访问效率,导致整体系统性能偏低。
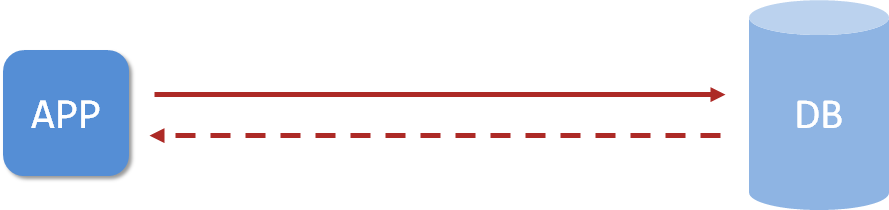
应用程序直接与数据库打交道,访问效率低
为了改善上述现象,开发者通常会在应用程序与数据库之间建立一种临时的数据存储机制,该区域中的数据在内存中保存,读写速度较快,可以有效解决数据库访问效率低下的问题。这一块临时存储数据的区域就是缓存。
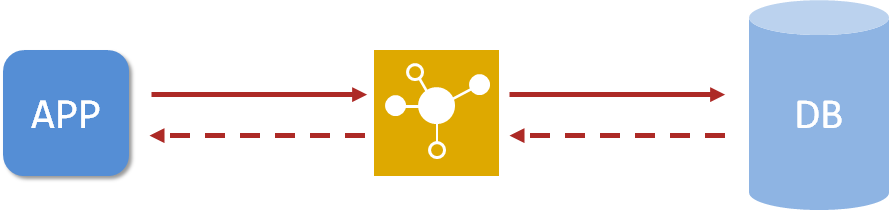
使用缓存后,应用程序与缓存打交道,缓存与数据库打交道,数据访问效率提高
缓存是什么?缓存是一种介于数据永久存储介质与应用程序之间的数据临时存储介质,使用缓存可以有效的减少低速数据读取过程的次数(例如磁盘 IO),提高系统性能。此外缓存不仅可以用于提高永久性存储介质的数据读取效率,还可以提供临时的数据存储空间。而 springboot 提供了对市面上几乎所有的缓存技术进行整合的方案,下面就一起开启 springboot 整合缓存之旅。
# SpringBoot 内置缓存解决方案
springboot 技术提供有内置的缓存解决方案,可以帮助开发者快速开启缓存技术,并使用缓存技术进行数据的快速操作,例如读取缓存数据和写入数据到缓存。
步骤①:导入 springboot 提供的缓存技术对应的 starter
1 | <dependency> |
步骤②:启用缓存,在引导类上方标注注解 @EnableCaching 配置 springboot 程序中可以使用缓存
1 |
|
步骤③:设置操作的数据是否使用缓存
1 |
|
在业务方法上面使用注解 @Cacheable 声明当前方法的返回值放入缓存中,其中要指定缓存的存储位置,以及缓存中保存当前方法返回值对应的名称。上例中 value 属性描述缓存的存储位置,可以理解为是一个存储空间名,key 属性描述了缓存中保存数据的名称,使用 #id 读取形参中的 id 值作为缓存名称。
使用 @Cacheable 注解后,执行当前操作,如果发现对应名称在缓存中没有数据,就正常读取数据,然后放入缓存;如果对应名称在缓存中有数据,就终止当前业务方法执行,直接返回缓存中的数据。
# 手机验证码案例
为了便于下面演示各种各样的缓存技术,我们创建一个手机验证码的案例环境,模拟使用缓存保存手机验证码的过程。
手机验证码案例需求如下:
- 输入手机号获取验证码,组织文档以短信形式发送给用户(页面模拟)
- 输入手机号和验证码验证结果
为了描述上述操作,我们制作两个表现层接口,一个用来模拟发送短信的过程,其实就是根据用户提供的手机号生成一个验证码,然后放入缓存,另一个用来模拟验证码校验的过程,其实就是使用传入的手机号和验证码进行匹配,并返回最终匹配结果。下面直接制作本案例的模拟代码,先以上例中 springboot 提供的内置缓存技术来完成当前案例的制作。
步骤①:导入 springboot 提供的缓存技术对应的 starter
1 | <dependency> |
步骤②:启用缓存,在引导类上方标注注解 @EnableCaching 配置 springboot 程序中可以使用缓存
1 |
|
步骤③:定义验证码对应的实体类,封装手机号与验证码两个属性
1 |
|
步骤④:定义验证码功能的业务层接口与实现类
1 | public interface SMSCodeService { |
获取验证码后,当验证码失效时必须重新获取验证码,因此在获取验证码的功能上不能使用 @Cacheable 注解,@Cacheable 注解是缓存中没有值则放入值,缓存中有值则取值。此处的功能仅仅是生成验证码并放入缓存,并不具有从缓存中取值的功能,因此不能使用 @Cacheable 注解,应该使用仅具有向缓存中保存数据的功能,使用 @CachePut 注解即可。
对于校验验证码的功能建议放入工具类中进行。
步骤⑤:定义验证码的生成策略与根据手机号读取验证码的功能
1 |
|
步骤⑥:定义验证码功能的 web 层接口,一个方法用于提供手机号获取验证码,一个方法用于提供手机号和验证码进行校验
1 |
|
# SpringBoot 整合 Ehcache 缓存
手机验证码的案例已经完成了,下面就开始 springboot 整合各种各样的缓存技术,第一个整合 Ehcache 技术。Ehcache 是一种缓存技术,使用 springboot 整合 Ehcache 其实就是变更一下缓存技术的实现方式,话不多说,直接开整
步骤①:导入 Ehcache 的坐标
1 | <dependency> |
此处为什么不是导入 Ehcache 的 starter,而是导入技术坐标呢?其实 springboot 整合缓存技术做的是通用格式,不管你整合哪种缓存技术,只是实现变化了,操作方式一样。这也体现出 springboot 技术的优点,统一同类技术的整合方式。
步骤②:配置缓存技术实现使用 Ehcache
1 | spring: |
配置缓存的类型 type 为 ehcache,此处需要说明一下,当前 springboot 可以整合的缓存技术中包含有 ehcach,所以可以这样书写。其实这个 type 不可以随便写的,不是随便写一个名称就可以整合的。
由于 ehcache 的配置有独立的配置文件格式,因此还需要指定 ehcache 的配置文件,以便于读取相应配置
1 |
|
注意前面的案例中,设置了数据保存的位置是 smsCode
1 |
|
这个设定需要保障 ehcache 中有一个缓存空间名称叫做 smsCode 的配置,前后要统一。在企业开发过程中,通过设置不同名称的 cache 来设定不同的缓存策略,应用于不同的缓存数据。
到这里 springboot 整合 Ehcache 就做完了,可以发现一点,原始代码没有任何修改,仅仅是加了一组配置就可以变更缓存供应商了,这也是 springboot 提供了统一的缓存操作接口的优势,变更实现并不影响原始代码的书写。
总结
- springboot 使用 Ehcache 作为缓存实现需要导入 Ehcache 的坐标
- 修改设置,配置缓存供应商为 ehcache,并提供对应的缓存配置文件
# SpringBoot 整合 Redis 缓存
上节使用 Ehcache 替换了 springboot 内置的缓存技术,其实 springboot 支持的缓存技术还很多,下面使用 redis 技术作为缓存解决方案来实现手机验证码案例。
比对使用 Ehcache 的过程,加坐标,改缓存实现类型为 ehcache,做 Ehcache 的配置。如果还成 redis 做缓存呢?一模一样,加坐标,改缓存实现类型为 redis,做 redis 的配置。差别之处只有一点,redis 的配置可以在 yml 文件中直接进行配置,无需制作独立的配置文件。
步骤①:导入 redis 的坐标
1 | <dependency> |
步骤②:配置缓存技术实现使用 redis
1 | spring: |
如果需要对 redis 作为缓存进行配置,注意不是对原始的 redis 进行配置,而是配置 redis 作为缓存使用相关的配置,隶属于 spring.cache.redis 节点下,注意不要写错位置了。
1 | spring: |
总结
- springboot 使用 redis 作为缓存实现需要导入 redis 的坐标
- 修改设置,配置缓存供应商为 redis,并提供对应的缓存配置
# SpringBoot 整合 Memcached 缓存
目前我们已经掌握了 3 种缓存解决方案的配置形式,分别是 springboot 内置缓存,ehcache 和 redis,本节研究一下国内比较流行的一款缓存 memcached。
按照之前的套路,其实变更缓存并不繁琐,但是 springboot 并没有支持使用 memcached 作为其缓存解决方案,也就是说在 type 属性中没有 memcached 的配置选项,这里就需要更变一下处理方式了。在整合之前先安装 memcached。
安装
windows 版安装包下载地址:https://www.runoob.com/memcached/window-install-memcached.html
下载的安装包是解压缩就能使用的 zip 文件,解压缩完毕后会得到如下文件
可执行文件只有一个 memcached.exe,使用该文件可以将 memcached 作为系统服务启动,执行此文件时会出现报错信息,如下:
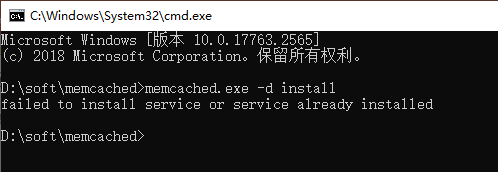
此处出现问题的原因是注册系统服务时需要使用管理员权限,当前账号权限不足导致安装服务失败,切换管理员账号权限启动命令行
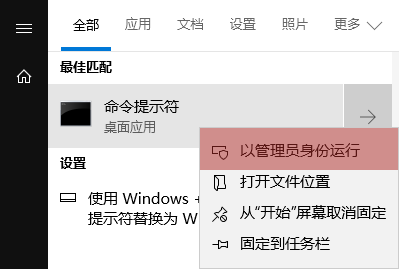
然后再次执行安装服务的命令即可,如下:
1 | memcached.exe -d install |
服务安装完毕后可以使用命令启动和停止服务,如下:
1 | memcached.exe -d start # 启动服务 |
也可以在任务管理器中进行服务状态的切换
变更缓存为 Memcached
由于 memcached 未被 springboot 收录为缓存解决方案,因此使用 memcached 需要通过手工硬编码的方式来使用,于是前面的套路都不适用了,需要自己写了。
memcached 目前提供有三种客户端技术,分别是 Memcached Client for Java、SpyMemcached 和 Xmemcached,其中性能指标各方面最好的客户端是 Xmemcached,本次整合就使用这个作为客户端实现技术了。下面开始使用 Xmemcached
步骤①:导入 xmemcached 的坐标
1 | <dependency> |
步骤②:配置 memcached,制作 memcached 的配置类
1 |
|
memcached 默认对外服务端口 11211。
步骤③:使用 xmemcached 客户端操作缓存,注入 MemcachedClient 对象
1 |
|
设置值到缓存中使用 set 操作,取值使用 get 操作,其实更符合我们开发者的习惯。
上述代码中对于服务器的配置使用硬编码写死到了代码中,将此数据提取出来,做成独立的配置属性。
定义配置属性
以下过程采用前期学习的属性配置方式进行,当前操作有助于理解原理篇中的很多知识。
-
定义配置类,加载必要的配置属性,读取配置文件中 memcached 节点信息
1
2
3
4
5
6
7
8
public class XMemcachedProperties {
private String servers;
private int poolSize;
private long opTimeout;
} -
定义 memcached 节点信息
1
2
3
4memcached:
servers: localhost:11211
poolSize: 10
opTimeout: 3000 -
在 memcached 配置类中加载信息
1 |
|
总结
- memcached 安装后需要启动对应服务才可以对外提供缓存功能,安装 memcached 服务需要基于 windows 系统管理员权限
- 由于 springboot 没有提供对 memcached 的缓存整合方案,需要采用手工编码的形式创建 xmemcached 客户端操作缓存
- 导入 xmemcached 坐标后,创建 memcached 配置类,注册 MemcachedClient 对应的 bean,用于操作缓存
- 初始化 MemcachedClient 对象所需要使用的属性可以通过自定义配置属性类的形式加载
思考
到这里已经完成了三种缓存的整合,其中 redis 和 mongodb 需要安装独立的服务器,连接时需要输入对应的服务器地址,这种是远程缓存,Ehcache 是一个典型的内存级缓存,因为它什么也不用安装,启动后导入 jar 包就有缓存功能了。这个时候就要问了,能不能这两种缓存一起用呢?咱们下节再说。
# SpringBoot 整合 jetcache 缓存
目前我们使用的缓存都是要么 A 要么 B,能不能 AB 一起用呢?这一节就解决这个问题。springboot 针对缓存的整合仅仅停留在用缓存上面,如果缓存自身不支持同时支持 AB 一起用,springboot 也没办法,所以要想解决 AB 缓存一起用的问题,就必须找一款缓存能够支持 AB 两种缓存一起用,有这种缓存吗?还真有,阿里出品,jetcache。
jetcache 严格意义上来说,并不是一个缓存解决方案,只能说他算是一个缓存框架,然后把别的缓存放到 jetcache 中管理,这样就可以支持 AB 缓存一起用了。并且 jetcache 参考了 springboot 整合缓存的思想,整体技术使用方式和 springboot 的缓存解决方案思想非常类似。下面咱们就先把 jetcache 用起来,然后再说它里面的一些小的功能。
做之前要先明确一下,jetcache 并不是随便拿两个缓存都能拼到一起去的。目前 jetcache 支持的缓存方案本地缓存支持两种,远程缓存支持两种,分别如下:
- 本地缓存(Local)
- LinkedHashMap
- Caffeine
- 远程缓存(Remote)
- Redis
- Tair
其实也有人问我,为什么 jetcache 只支持 2+2 这么 4 款缓存呢?阿里研发这个技术其实主要是为了满足自身的使用需要。最初肯定只有 1+1 种,逐步变化成 2+2 种。下面就以 LinkedHashMap+Redis 的方案实现本地与远程缓存方案同时使用。
# 纯远程方案
步骤①:导入 springboot 整合 jetcache 对应的坐标 starter,当前坐标默认使用的远程方案是 redis
1 | <dependency> |
步骤②:远程方案基本配置
1 | jetcache: |
其中 poolConfig 是必配项,否则会报错
步骤③:启用缓存,在引导类上方标注注解 @EnableCreateCacheAnnotation 配置 springboot 程序中可以使用注解的形式创建缓存
1 |
|
步骤④:创建缓存对象 Cache,并使用注解 @CreateCache 标记当前缓存的信息,然后使用 Cache 对象的 API 操作缓存,put 写缓存,get 读缓存。
1 |
|
通过上述 jetcache 使用远程方案连接 redis 可以看出,jetcache 操作缓存时的接口操作更符合开发者习惯,使用缓存就先获取缓存对象 Cache,放数据进去就是 put,取数据出来就是 get,更加简单易懂。并且 jetcache 操作缓存时,可以为某个缓存对象设置过期时间,将同类型的数据放入缓存中,方便有效周期的管理。
上述方案中使用的是配置中定义的 default 缓存,其实这个 default 是个名字,可以随便写,也可以随便加。例如再添加一种缓存解决方案,参照如下配置进行:
1 | jetcache: |
如果想使用名称是 sms 的缓存,需要再创建缓存时指定参数 area,声明使用对应缓存即可
1 |
|
# 纯本地方案
远程方案中,配置中使用 remote 表示远程,换成 local 就是本地,只不过类型不一样而已。
步骤①:导入 springboot 整合 jetcache 对应的坐标 starter
1 | <dependency> |
步骤②:本地缓存基本配置
1 | jetcache: |
为了加速数据获取时 key 的匹配速度,jetcache 要求指定 key 的类型转换器。简单说就是,如果你给了一个 Object 作为 key 的话,我先用 key 的类型转换器给转换成字符串,然后再保存。等到获取数据时,仍然是先使用给定的 Object 转换成字符串,然后根据字符串匹配。由于 jetcache 是阿里的技术,这里推荐 key 的类型转换器使用阿里的 fastjson。
步骤③:启用缓存
1 |
|
步骤④:创建缓存对象 Cache 时,标注当前使用本地缓存
1 |
|
cacheType 控制当前缓存使用本地缓存还是远程缓存,配置 cacheType=CacheType.LOCAL 即使用本地缓存。
# 本地 + 远程方案
本地和远程方法都有了,两种方案一起使用如何配置呢?其实就是将两种配置合并到一起就可以了。
1 | jetcache: |
在创建缓存的时候,配置 cacheType 为 BOTH 即则本地缓存与远程缓存同时使用。
1 |
|
cacheType 如果不进行配置,默认值是 REMOTE,即仅使用远程缓存方案。关于 jetcache 的配置,参考以下信息
| 属性 | 默认值 | 说明 |
|---|---|---|
| jetcache.statIntervalMinutes | 0 | 统计间隔,0 表示不统计 |
| jetcache.hiddenPackages | 无 | 自动生成 name 时,隐藏指定的包名前缀 |
| jetcache.[local|remote].${area}.type | 无 | 缓存类型,本地支持 linkedhashmap、caffeine,远程支持 redis、tair |
| jetcache.[local|remote].${area}.keyConvertor | 无 | key 转换器,当前仅支持 fastjson |
| jetcache.[local|remote].${area}.valueEncoder | java | 仅 remote 类型的缓存需要指定,可选 java 和 kryo |
| jetcache.[local|remote].${area}.valueDecoder | java | 仅 remote 类型的缓存需要指定,可选 java 和 kryo |
| jetcache.[local|remote].${area}.limit | 100 | 仅 local 类型的缓存需要指定,缓存实例最大元素数 |
| jetcache.[local|remote].${area}.expireAfterWriteInMillis | 无穷大 | 默认过期时间,毫秒单位 |
| jetcache.local.${area}.expireAfterAccessInMillis | 0 | 仅 local 类型的缓存有效,毫秒单位,最大不活动间隔 |
以上方案仅支持手工控制缓存,但是 springcache 方案中的方法缓存特别好用,给一个方法添加一个注解,方法就会自动使用缓存。jetcache 也提供了对应的功能,即方法缓存。
方法缓存
jetcache 提供了方法缓存方案,只不过名称变更了而已。在对应的操作接口上方使用注解 @Cached 即可
步骤①:导入 springboot 整合 jetcache 对应的坐标 starter
1 | <dependency> |
步骤②:配置缓存
1 | jetcache: |
由于 redis 缓存中不支持保存对象,因此需要对 redis 设置当 Object 类型数据进入到 redis 中时如何进行类型转换。需要配置 keyConvertor 表示 key 的类型转换方式,同时标注 value 的转换类型方式,值进入 redis 时是 java 类型,标注 valueEncode 为 java,值从 redis 中读取时转换成 java,标注 valueDecode 为 java。
注意,为了实现 Object 类型的值进出 redis,需要保障进出 redis 的 Object 类型的数据必须实现序列化接口。
1 |
|
步骤③:启用缓存时开启方法缓存功能,并配置 basePackages,说明在哪些包中开启方法缓存
1 |
|
步骤④:使用注解 @Cached 标注当前方法使用缓存
1 |
|
# 远程方案的数据同步
由于远程方案中 redis 保存的数据可以被多个客户端共享,这就存在了数据同步问题。jetcache 提供了 3 个注解解决此问题,分别在更新、删除操作时同步缓存数据,和读取缓存时定时刷新数据
更新缓存
1 |
|
删除缓存
1 |
|
定时刷新缓存
1 |
|
# 数据报表
jetcache 还提供有简单的数据报表功能,帮助开发者快速查看缓存命中信息,只需要添加一个配置即可
1 | jetcache: |
设置后,每 1 分钟在控制台输出缓存数据命中信息
1 | [DefaultExecutor] c.alicp.jetcache.support.StatInfoLogger : jetcache stat from 2022-02-28 09:32:15,892 to 2022-02-28 09:33:00,003 |
总结
- jetcache 是一个类似于 springcache 的缓存解决方案,自身不具有缓存功能,它提供有本地缓存与远程缓存多级共同使用的缓存解决方案
- jetcache 提供的缓存解决方案受限于目前支持的方案,本地缓存支持两种,远程缓存支持两种
- 注意数据进入远程缓存时的类型转换问题
- jetcache 提供方法缓存,并提供了对应的缓存更新与刷新功能
- jetcache 提供有简单的缓存信息命中报表方便开发者即时监控缓存数据命中情况
思考
jetcache 解决了前期使用缓存方案单一的问题,但是仍然不能灵活的选择缓存进行搭配使用,是否存在一种技术可以灵活的搭配各种各样的缓存使用呢?有,咱们下一节再讲。
# SpringBoot 整合 j2cache 缓存
jetcache 可以在限定范围内构建多级缓存,但是灵活性不足,不能随意搭配缓存,本节介绍一种可以随意搭配缓存解决方案的缓存整合框架,j2cache。下面就来讲解如何使用这种缓存框架,以 Ehcache 与 redis 整合为例:
步骤①:导入 j2cache、redis、ehcache 坐标
1 | <dependency> |
j2cache 的 starter 中默认包含了 redis 坐标,官方推荐使用 redis 作为二级缓存,因此此处无需导入 redis 坐标
步骤②:配置一级与二级缓存,并配置一二级缓存间数据传递方式,配置书写在名称为 j2cache.properties 的文件中。如果使用 ehcache 还需要单独添加 ehcache 的配置文件
1 | # 1级缓存 |
此处配置不能乱配置,需要参照官方给出的配置说明进行。例如 1 级供应商选择 ehcache,供应商名称仅仅是一个 ehcache,但是 2 级供应商选择 redis 时要写专用的 Spring 整合 Redis 的供应商类名 SpringRedisProvider,而且这个名称并不是所有的 redis 包中能提供的,也不是 spring 包中提供的。因此配置 j2cache 必须参照官方文档配置,而且还要去找专用的整合包,导入对应坐标才可以使用。
一级与二级缓存最重要的一个配置就是两者之间的数据沟通方式,此类配置也不是随意配置的,并且不同的缓存解决方案提供的数据沟通方式差异化很大,需要查询官方文档进行设置。
步骤③:使用缓存
1 |
|
j2cache 的使用和 jetcache 比较类似,但是无需开启使用的开关,直接定义缓存对象即可使用,缓存对象名 CacheChannel。
j2cache 的使用不复杂,配置是 j2cache 的核心,毕竟是一个整合型的缓存框架。缓存相关的配置过多,可以查阅 j2cache-core 核心包中的 j2cache.properties 文件中的说明。如下:
1 | #J2Cache configuration |
总结
- j2cache 是一个缓存框架,自身不具有缓存功能,它提供多种缓存整合在一起使用的方案
- j2cache 需要通过复杂的配置设置各级缓存,以及缓存之间数据交换的方式
- j2cache 操作接口通过 CacheChannel 实现
# KF-5-2. 任务
springboot 整合第三方技术第二部分我们来说说任务系统,其实这里说的任务系统指的是定时任务。定时任务是企业级开发中必不可少的组成部分,诸如长周期业务数据的计算,例如年度报表,诸如系统脏数据的处理,再比如系统性能监控报告,还有抢购类活动的商品上架,这些都离不开定时任务。本节将介绍两种不同的定时任务技术。
# Quartz
Quartz 技术是一个比较成熟的定时任务框架,怎么说呢?有点繁琐,用过的都知道,配置略微复杂。springboot 对其进行整合后,简化了一系列的配置,将很多配置采用默认设置,这样开发阶段就简化了很多。再学习 springboot 整合 Quartz 前先普及几个 Quartz 的概念。
- 工作(Job):用于定义具体执行的工作
- 工作明细(JobDetail):用于描述定时工作相关的信息
- 触发器(Trigger):描述了工作明细与调度器的对应关系
- 调度器(Scheduler):用于描述触发工作的执行规则,通常使用 cron 表达式定义规则
简单说就是你定时干什么事情,这就是工作,工作不可能就是一个简单的方法,还要设置一些明细信息。工作啥时候执行,设置一个调度器,可以简单理解成设置一个工作执行的时间。工作和调度都是独立定义的,它们两个怎么配合到一起呢?用触发器。完了,就这么多。下面开始 springboot 整合 Quartz。
步骤①:导入 springboot 整合 Quartz 的 starter
1 | <dependency> |
步骤②:定义任务 Bean,按照 Quartz 的开发规范制作,继承 QuartzJobBean
1 | public class MyQuartz extends QuartzJobBean { |
步骤③:创建 Quartz 配置类,定义工作明细(JobDetail)与触发器的(Trigger)bean
1 |
|
工作明细中要设置对应的具体工作,使用 newJob () 操作传入对应的工作任务类型即可。
触发器需要绑定任务,使用 forJob () 操作传入绑定的工作明细对象。此处可以为工作明细设置名称然后使用名称绑定,也可以直接调用对应方法绑定。触发器中最核心的规则是执行时间,此处使用调度器定义执行时间,执行时间描述方式使用的是 cron 表达式。有关 cron 表达式的规则,各位小伙伴可以去参看相关课程学习,略微复杂,而且格式不能乱设置,不是写个格式就能用的,写不好就会出现冲突问题。
总结
- springboot 整合 Quartz 就是将 Quartz 对应的核心对象交给 spring 容器管理,包含两个对象,JobDetail 和 Trigger 对象
- JobDetail 对象描述的是工作的执行信息,需要绑定一个 QuartzJobBean 类型的对象
- Trigger 对象定义了一个触发器,需要为其指定绑定的 JobDetail 是哪个,同时要设置执行周期调度器
思考
上面的操作看上去不多,但是 Quartz 将其中的对象划分粒度过细,导致开发的时候有点繁琐,spring 针对上述规则进行了简化,开发了自己的任务管理组件 ——Task,如何用呢?咱们下节再说。
# Task
spring 根据定时任务的特征,将定时任务的开发简化到了极致。怎么说呢?要做定时任务总要告诉容器有这功能吧,然后定时执行什么任务直接告诉对应的 bean 什么时间执行就行了,就这么简单,一起来看怎么做
步骤①:开启定时任务功能,在引导类上开启定时任务功能的开关,使用注解 @EnableScheduling
1 |
|
步骤②:定义 Bean,在对应要定时执行的操作上方,使用注解 @Scheduled 定义执行的时间,执行时间的描述方式还是 cron 表达式
1 |
|
完事,这就完成了定时任务的配置。总体感觉其实什么东西都没少,只不过没有将所有的信息都抽取成 bean,而是直接使用注解绑定定时执行任务的事情而已。
如何想对定时任务进行相关配置,可以通过配置文件进行
1 | spring: |
总结
-
spring task 需要使用注解 @EnableScheduling 开启定时任务功能
-
为定时执行的的任务设置执行周期,描述方式 cron 表达式
# KF-5-3. 邮件
springboot 整合第三方技术第三部分我们来说说邮件系统,发邮件是 java 程序的基本操作,springboot 整合 javamail 其实就是简化开发。不熟悉邮件的小伙伴可以先学习完 javamail 的基础操作,再来看这一部分内容才能感触到 springboot 整合 javamail 究竟简化了哪些操作。简化的多码?其实不多,差别不大,只是还个格式而已。
学习邮件发送之前先了解 3 个概念,这些概念规范了邮件操作过程中的标准。
- SMTP(Simple Mail Transfer Protocol):简单邮件传输协议,用于发送电子邮件的传输协议
- POP3(Post Office Protocol - Version 3):用于接收电子邮件的标准协议
- IMAP(Internet Mail Access Protocol):互联网消息协议,是 POP3 的替代协议
简单说就是 SMPT 是发邮件的标准,POP3 是收邮件的标准,IMAP 是对 POP3 的升级。我们制作程序中操作邮件,通常是发邮件,所以 SMTP 是使用的重点,收邮件大部分都是通过邮件客户端完成,所以开发收邮件的代码极少。除非你要读取邮件内容,然后解析,做邮件功能的统一处理。例如 HR 的邮箱收到求职者的简历,可以读取后统一处理。但是为什么不制作独立的投递简历的系统呢?所以说,好奇怪的需求,因为要想收邮件就要规范发邮件的人的书写格式,这个未免有点强人所难,并且极易收到外部攻击,你不可能使用白名单来收邮件。如果能使用白名单来收邮件然后解析邮件,还不如开发个系统给白名单中的人专用呢,更安全,总之就是鸡肋了。下面就开始学习 springboot 如何整合 javamail 发送邮件。
# 发送简单邮件
步骤①:导入 springboot 整合 javamail 的 starter
1 | <dependency> |
步骤②:配置邮箱的登录信息
1 | spring: |
java 程序仅用于发送邮件,邮件的功能还是邮件供应商提供的,所以这里是用别人的邮件服务,要配置对应信息。
host 配置的是提供邮件服务的主机协议,当前程序仅用于发送邮件,因此配置的是 smtp 的协议。
password 并不是邮箱账号的登录密码,是邮件供应商提供的一个加密后的密码,也是为了保障系统安全性。不然外部人员通过地址访问下载了配置文件,直接获取到了邮件密码就会有极大的安全隐患。有关该密码的获取每个邮件供应商提供的方式都不一样,此处略过。可以到邮件供应商的设置页面找 POP3 或 IMAP 这些关键词找到对应的获取位置。下例仅供参考:

步骤③:使用 JavaMailSender 接口发送邮件
1 |
|
将发送邮件的必要信息(发件人、收件人、标题、正文)封装到 SimpleMailMessage 对象中,可以根据规则设置发送人昵称等。
# 发送多组件邮件(附件、复杂正文)
发送简单邮件仅需要提供对应的 4 个基本信息就可以了,如果想发送复杂的邮件,需要更换邮件对象。使用 MimeMessage 可以发送特殊的邮件。
发送网页正文邮件
1 |
|
发送带有附件的邮件
1 |
|
总结
- springboot 整合 javamail 其实就是简化了发送邮件的客户端对象 JavaMailSender 的初始化过程,通过配置的形式加载信息简化开发过程
# KF-5-4. 消息
springboot 整合第三方技术最后一部分我们来说说消息中间件,首先先介绍一下消息的应用。
# 消息的概念
从广义角度来说,消息其实就是信息,但是和信息又有所不同。信息通常被定义为一组数据,而消息除了具有数据的特征之外,还有消息的来源与接收的概念。通常发送消息的一方称为消息的生产者,接收消息的一方称为消息的消费者。这样比较后,发现其实消息和信息差别还是很大的。
为什么要设置生产者和消费者呢?这就是要说到消息的意义了。信息通常就是一组数据,但是消息由于有了生产者和消费者,就出现了消息中所包含的信息可以被二次解读,生产者发送消息,可以理解为生产者发送了一个信息,也可以理解为生产者发送了一个命令;消费者接收消息,可以理解为消费者得到了一个信息,也可以理解为消费者得到了一个命令。对比一下我们会发现信息是一个基本数据,而命令则可以关联下一个行为动作,这样就可以理解为基于接收的消息相当于得到了一个行为动作,使用这些行为动作就可以组织成一个业务逻辑,进行进一步的操作。总的来说,消息其实也是一组信息,只是为其赋予了全新的含义,因为有了消息的流动,并且是有方向性的流动,带来了基于流动的行为产生的全新解读。开发者就可以基于消息的这种特殊解,将其换成代码中的指令。
对于消息的理解,初学者总认为消息内部的数据非常复杂,这是一个误区。比如我发送了一个消息,要求接受者翻译发送过去的内容。初学者会认为消息中会包含被翻译的文字,已经本次操作要执行翻译操作而不是打印操作。其实这种现象有点过度解读了,发送的消息中仅仅包含被翻译的文字,但是可以通过控制不同的人接收此消息来确认要做的事情。例如发送被翻译的文字仅到 A 程序,而 A 程序只能进行翻译操作,这样就可以发送简单的信息完成复杂的业务了,是通过接收消息的主体不同,进而执行不同的操作,而不会在消息内部定义数据的操作行为,当然如果开发者希望消息中包含操作种类信息也是可以的,只是提出消息的内容可以更简单,更单一。
对于消息的生产者与消费者的工作模式,还可以将消息划分成两种模式,同步消费与异步消息。
所谓同步消息就是生产者发送完消息,等待消费者处理,消费者处理完将结果告知生产者,然后生产者继续向下执行业务。这种模式过于卡生产者的业务执行连续性,在现在的企业级开发中,上述这种业务场景通常不会采用消息的形式进行处理。
所谓异步消息就是生产者发送完消息,无需等待消费者处理完毕,生产者继续向下执行其他动作。比如生产者发送了一个日志信息给日志系统,发送过去以后生产者就向下做其他事情了,无需关注日志系统的执行结果。日志系统根据接收到的日志信息继续进行业务执行,是单纯的记录日志,还是记录日志并报警,这些和生产者无关,这样生产者的业务执行效率就会大幅度提升。并且可以通过添加多个消费者来处理同一个生产者发送的消息来提高系统的高并发性,改善系统工作效率,提高用户体验。一旦某一个消费者由于各种问题宕机了,也不会对业务产生影响,提高了系统的高可用性。
以上简单的介绍了一下消息这种工作模式存在的意义,希望对各位学习者有所帮助。
# Java 处理消息的标准规范
目前企业级开发中广泛使用的消息处理技术共三大类,具体如下:
- JMS
- AMQP
- MQTT
为什么是三大类,而不是三个技术呢?因为这些都是规范,就想 JDBC 技术,是个规范,开发针对规范开发,运行还要靠实现类,例如 MySQL 提供了 JDBC 的实现,最终运行靠的还是实现。并且这三类规范都是针对异步消息进行处理的,也符合消息的设计本质,处理异步的业务。对以上三种消息规范做一下普及
# JMS
JMS(Java Message Service), 这是一个规范,作用等同于 JDBC 规范,提供了与消息服务相关的 API 接口。
JMS 消息模型
JMS 规范中规范了消息有两种模型。分别是点对点模型和发布订阅模型。
点对点模型:peer-2-peer,生产者会将消息发送到一个保存消息的容器中,通常使用队列模型,使用队列保存消息。一个队列的消息只能被一个消费者消费,或未被及时消费导致超时。这种模型下,生产者和消费者是一对一绑定的。
发布订阅模型:publish-subscribe,生产者将消息发送到一个保存消息的容器中,也是使用队列模型来保存。但是消息可以被多个消费者消费,生产者和消费者完全独立,相互不需要感知对方的存在。
以上这种分类是从消息的生产和消费过程来进行区分,针对消息所包含的信息不同,还可以进行不同类别的划分。
JMS 消息种类
根据消息中包含的数据种类划分,可以将消息划分成 6 种消息。
- TextMessage
- MapMessage
- BytesMessage
- StreamMessage
- ObjectMessage
- Message (只有消息头和属性)
JMS 主张不同种类的消息,消费方式不同,可以根据使用需要选择不同种类的消息。但是这一点也成为其诟病之处,后面再说。整体上来说,JMS 就是典型的保守派,什么都按照 J2EE 的规范来,做一套规范,定义若干个标准,每个标准下又提供一大批 API。目前对 JMS 规范实现的消息中间件技术还是挺多的,毕竟是皇家御用,肯定有人舔,例如 ActiveMQ、Redis、HornetMQ。但是也有一些不太规范的实现,参考 JMS 的标准设计,但是又不完全满足其规范,例如:RabbitMQ、RocketMQ。
# AMQP
JMS 的问世为消息中间件提供了很强大的规范性支撑,但是使用的过程中就开始被人诟病,比如 JMS 设置的极其复杂的多种类消息处理机制。本来分门别类处理挺好的,为什么会被诟病呢?原因就在于 JMS 的设计是 J2EE 规范,站在 Java 开发的角度思考问题。但是现实往往是复杂度很高的。比如我有一个.NET 开发的系统 A,有一个 Java 开发的系统 B,现在要从 A 系统给 B 系统发业务消息,结果两边数据格式不统一,没法操作。JMS 不是可以统一数据格式吗?提供了 6 种数据种类,总有一款适合你啊。NO,一个都不能用。因为 A 系统的底层语言不是 Java 语言开发的,根本不支持那些对象。这就意味着如果想使用现有的业务系统 A 继续开发已经不可能了,必须推翻重新做使用 Java 语言开发的 A 系统。
这时候有人就提出说,你搞那么复杂,整那么多种类干什么?找一种大家都支持的消息数据类型不就解决这个跨平台的问题了吗?大家一想,对啊,于是 AMQP 孕育而生。
单从上面的说明中其实可以明确感知到,AMQP 的出现解决的是消息传递时使用的消息种类的问题,化繁为简,但是其并没有完全推翻 JMS 的操作 API,所以说 AMQP 仅仅是一种协议,规范了数据传输的格式而已。
AMQP(advanced message queuing protocol):一种协议(高级消息队列协议,也是消息代理规范),规范了网络交换的数据格式,兼容 JMS 操作。
优点
具有跨平台性,服务器供应商,生产者,消费者可以使用不同的语言来实现
JMS 消息种类
AMQP 消息种类:byte []
AMQP 在 JMS 的消息模型基础上又进行了进一步的扩展,除了点对点和发布订阅的模型,开发了几种全新的消息模型,适应各种各样的消息发送。
AMQP 消息模型
- direct exchange
- fanout exchange
- topic exchange
- headers exchange
- system exchange
目前实现了 AMQP 协议的消息中间件技术也很多,而且都是较为流行的技术,例如:RabbitMQ、StormMQ、RocketMQ
# MQTT
MQTT(Message Queueing Telemetry Transport)消息队列遥测传输,专为小设备设计,是物联网(IOT)生态系统中主要成分之一。由于与 JavaEE 企业级开发没有交集,此处不作过多的说明。
除了上述 3 种 J2EE 企业级应用中广泛使用的三种异步消息传递技术,还有一种技术也不能忽略,Kafka。
# KafKa
Kafka,一种高吞吐量的分布式发布订阅消息系统,提供实时消息功能。Kafka 技术并不是作为消息中间件为主要功能的产品,但是其拥有发布订阅的工作模式,也可以充当消息中间件来使用,而且目前企业级开发中其身影也不少见。
本节内容讲围绕着上述内容中的几种实现方案讲解 springboot 整合各种各样的消息中间件。由于各种消息中间件必须先安装再使用,下面的内容采用 Windows 系统安装,降低各位学习者的学习难度,基本套路和之前学习 NoSQL 解决方案一样,先安装再整合。
# 购物订单发送手机短信案例
为了便于下面演示各种各样的消息中间件技术,我们创建一个购物过程生成订单时为用户发送短信的案例环境,模拟使用消息中间件实现发送手机短信的过程。
手机验证码案例需求如下:
-
执行下单业务时(模拟此过程),调用消息服务,将要发送短信的订单 id 传递给消息中间件
-
消息处理服务接收到要发送的订单 id 后输出订单 id(模拟发短信)
由于不涉及数据读写,仅开发业务层与表现层,其中短信处理的业务代码独立开发,代码如下:
订单业务
业务层接口
1 | public interface OrderService { |
模拟传入订单 id,执行下订单业务,参数为虚拟设定,实际应为订单对应的实体类
业务层实现
1 |
|
业务层转调短信处理的服务 MessageService
表现层服务
1 |
|
表现层对外开发接口,传入订单 id 即可(模拟)
短信处理业务
业务层接口
1 | public interface MessageService { |
短信处理业务层接口提供两个操作,发送要处理的订单 id 到消息中间件,另一个操作目前暂且设计成处理消息,实际消息的处理过程不应该是手动执行,应该是自动执行,到具体实现时再进行设计
业务层实现
1 |
|
短信处理业务层实现中使用集合先模拟消息队列,观察效果
表现层服务
1 |
|
短信处理表现层接口暂且开发出一个处理消息的入口,但是此业务是对应业务层中设计的模拟接口,实际业务不需要设计此接口。
下面开启 springboot 整合各种各样的消息中间件,从严格满足 JMS 规范的 ActiveMQ 开始
# SpringBoot 整合 ActiveMQ
ActiveMQ 是 MQ 产品中的元老级产品,早期标准 MQ 产品之一,在 AMQP 协议没有出现之前,占据了消息中间件市场的绝大部分份额,后期因为 AMQP 系列产品的出现,迅速走弱,目前仅在一些线上运行的产品中出现,新产品开发较少采用。
# 安装
windows 版安装包下载地址:https://activemq.apache.org/components/classic/download/
下载的安装包是解压缩就能使用的 zip 文件,解压缩完毕后会得到如下文件
启动服务器
1 | activemq.bat |
运行 bin 目录下的 win32 或 win64 目录下的 activemq.bat 命令即可,根据自己的操作系统选择即可,默认对外服务端口 61616。
访问 web 管理服务
ActiveMQ 启动后会启动一个 Web 控制台服务,可以通过该服务管理 ActiveMQ。
1 | http://127.0.0.1:8161/ |
web 管理服务默认端口 8161,访问后可以打开 ActiveMQ 的管理界面,如下:
首先输入访问用户名和密码,初始化用户名和密码相同,均为:admin,成功登录后进入管理后台界面,如下:
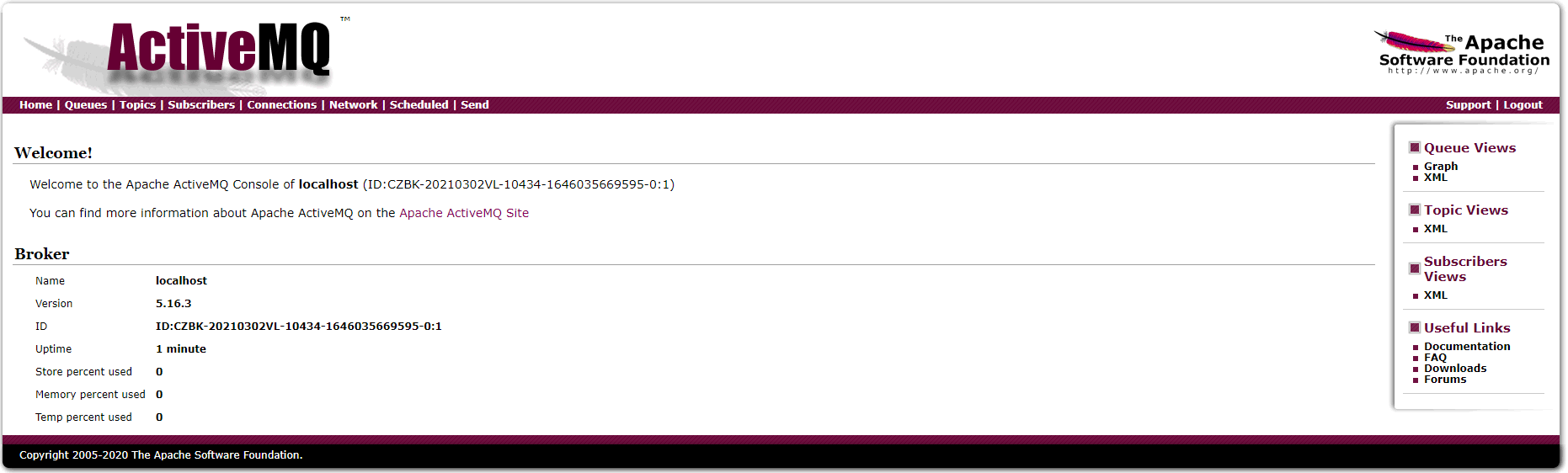
看到上述界面视为启动 ActiveMQ 服务成功。
启动失败
在 ActiveMQ 启动时要占用多个端口,以下为正常启动信息:
1 | wrapper | --> Wrapper Started as Console |
其中占用的端口有:61616、5672、61613、1883、61614,如果启动失败,请先管理对应端口即可。以下就是某个端口占用的报错信息,可以从抛出异常的位置看出,启动 5672 端口时端口被占用,显示 java.net.BindException: Address already in use: JVM_Bind。Windows 系统中终止端口运行的操作参看【命令行启动常见问题及解决方案】
1 | wrapper | --> Wrapper Started as Console |
# 整合
做了这么多 springboot 整合第三方技术,已经摸到门路了,加坐标,做配置,调接口,直接开工
步骤①:导入 springboot 整合 ActiveMQ 的 starter
1 | <dependency> |
步骤②:配置 ActiveMQ 的服务器地址
1 | spring: |
步骤③:使用 JmsMessagingTemplate 操作 ActiveMQ
1 |
|
发送消息需要先将消息的类型转换成字符串,然后再发送,所以是 convertAndSend,定义消息发送的位置,和具体的消息内容,此处使用 id 作为消息内容。
接收消息需要先将消息接收到,然后再转换成指定的数据类型,所以是 receiveAndConvert,接收消息除了提供读取的位置,还要给出转换后的数据的具体类型。
步骤④:使用消息监听器在服务器启动后,监听指定位置,当消息出现后,立即消费消息
1 |
|
使用注解 @JmsListener 定义当前方法监听 ActiveMQ 中指定名称的消息队列。
如果当前消息队列处理完还需要继续向下传递当前消息到另一个队列中使用注解 @SendTo 即可,这样即可构造连续执行的顺序消息队列。
步骤⑤:切换消息模型由点对点模型到发布订阅模型,修改 jms 配置即可
1 | spring: |
pub-sub-domain 默认值为 false,即点对点模型,修改为 true 后就是发布订阅模型。
总结
- springboot 整合 ActiveMQ 提供了 JmsMessagingTemplate 对象作为客户端操作消息队列
- 操作 ActiveMQ 需要配置 ActiveMQ 服务器地址,默认端口 61616
- 企业开发时通常使用监听器来处理消息队列中的消息,设置监听器使用注解 @JmsListener
- 配置 jms 的 pub-sub-domain 属性可以在点对点模型和发布订阅模型间切换消息模型
# SpringBoot 整合 RabbitMQ
RabbitMQ 是 MQ 产品中的目前较为流行的产品之一,它遵从 AMQP 协议。RabbitMQ 的底层实现语言使用的是 Erlang,所以安装 RabbitMQ 需要先安装 Erlang。
Erlang 安装
windows 版安装包下载地址:https😕/www.erlang.org/downloads
下载完毕后得到 exe 安装文件,一键傻瓜式安装,安装完毕需要重启,需要重启,需要重启。
安装的过程中可能会出现依赖 Windows 组件的提示,根据提示下载安装即可,都是自动执行的,如下:
Erlang 安装后需要配置环境变量,否则 RabbitMQ 将无法找到安装的 Erlang。需要配置项如下,作用等同 JDK 配置环境变量的作用。
- ERLANG_HOME
- PATH
# 安装
windows 版安装包下载地址:https://rabbitmq.com/install-windows.html
下载完毕后得到 exe 安装文件,一键傻瓜式安装,安装完毕后会得到如下文件
启动服务器
1 | rabbitmq-service.bat start # 启动服务 |
运行 sbin 目录下的 rabbitmq-service.bat 命令即可,start 参数表示启动,stop 参数表示退出,默认对外服务端口 5672。
注意:启动 rabbitmq 的过程实际上是开启 rabbitmq 对应的系统服务,需要管理员权限方可执行。
说明:有没有感觉 5672 的服务端口很熟悉?activemq 与 rabbitmq 有一个端口冲突问题,学习阶段无论操作哪一个?请确保另一个处于关闭状态。
说明:不喜欢命令行的小伙伴可以使用任务管理器中的服务页,找到 RabbitMQ 服务,使用鼠标右键菜单控制服务的启停。
访问 web 管理服务
RabbitMQ 也提供有 web 控制台服务,但是此功能是一个插件,需要先启用才可以使用。
1 | rabbitmq-plugins.bat list # 查看当前所有插件的运行状态 |
启动插件后可以在插件运行状态中查看是否运行,运行后通过浏览器即可打开服务后台管理界面
1 | http://localhost:15672 |
web 管理服务默认端口 15672,访问后可以打开 RabbitMQ 的管理界面,如下:
首先输入访问用户名和密码,初始化用户名和密码相同,均为:guest,成功登录后进入管理后台界面,如下:
# 整合 (direct 模型)
RabbitMQ 满足 AMQP 协议,因此不同的消息模型对应的制作不同,先使用最简单的 direct 模型开发。
步骤①:导入 springboot 整合 amqp 的 starter,amqp 协议默认实现为 rabbitmq 方案
1 | <dependency> |
步骤②:配置 RabbitMQ 的服务器地址
1 | spring: |
步骤③:初始化直连模式系统设置
由于 RabbitMQ 不同模型要使用不同的交换机,因此需要先初始化 RabbitMQ 相关的对象,例如队列,交换机等
1 |
|
队列 Queue 与直连交换机 DirectExchange 创建后,还需要绑定他们之间的关系 Binding,这样就可以通过交换机操作对应队列。
步骤④:使用 AmqpTemplate 操作 RabbitMQ
1 |
|
amqp 协议中的操作 API 接口名称看上去和 jms 规范的操作 API 接口很相似,但是传递参数差异很大。
步骤⑤:使用消息监听器在服务器启动后,监听指定位置,当消息出现后,立即消费消息
1 |
|
使用注解 @RabbitListener 定义当前方法监听 RabbitMQ 中指定名称的消息队列。
# 整合 (topic 模型)
步骤①:同上
步骤②:同上
步骤③:初始化主题模式系统设置
1 |
|
主题模式支持 routingKey 匹配模式,* 表示匹配一个单词,# 表示匹配任意内容,这样就可以通过主题交换机将消息分发到不同的队列中,详细内容请参看 RabbitMQ 系列课程。
| 匹配键 | topic.*.* | topic.# |
|---|---|---|
| topic.order.id | true | true |
| order.topic.id | false | false |
| topic.sm.order.id | false | true |
| topic.sm.id | false | true |
| topic.id.order | true | true |
| topic.id | false | true |
| topic.order | false | true |
步骤④:使用 AmqpTemplate 操作 RabbitMQ
1 |
|
发送消息后,根据当前提供的 routingKey 与绑定交换机时设定的 routingKey 进行匹配,规则匹配成功消息才会进入到对应的队列中。
步骤⑤:使用消息监听器在服务器启动后,监听指定队列
1 |
|
使用注解 @RabbitListener 定义当前方法监听 RabbitMQ 中指定名称的消息队列。
总结
- springboot 整合 RabbitMQ 提供了 AmqpTemplate 对象作为客户端操作消息队列
- 操作 ActiveMQ 需要配置 ActiveMQ 服务器地址,默认端口 5672
- 企业开发时通常使用监听器来处理消息队列中的消息,设置监听器使用注解 @RabbitListener
- RabbitMQ 有 5 种消息模型,使用的队列相同,但是交换机不同。交换机不同,对应的消息进入的策略也不同
# SpringBoot 整合 RocketMQ
RocketMQ 由阿里研发,后捐赠给 apache 基金会,目前是 apache 基金会顶级项目之一,也是目前市面上的 MQ 产品中较为流行的产品之一,它遵从 AMQP 协议。
# 安装
windows 版安装包下载地址:https://rocketmq.apache.org/
下载完毕后得到 zip 压缩文件,解压缩即可使用,解压后得到如下文件
RocketMQ 安装后需要配置环境变量,具体如下:
- ROCKETMQ_HOME
- PATH
- NAMESRV_ADDR (建议): 127.0.0.1:9876
关于 NAMESRV_ADDR 对于初学者来说建议配置此项,也可以通过命令设置对应值,操作略显繁琐,建议配置。系统学习 RocketMQ 知识后即可灵活控制该项。
RocketMQ 工作模式
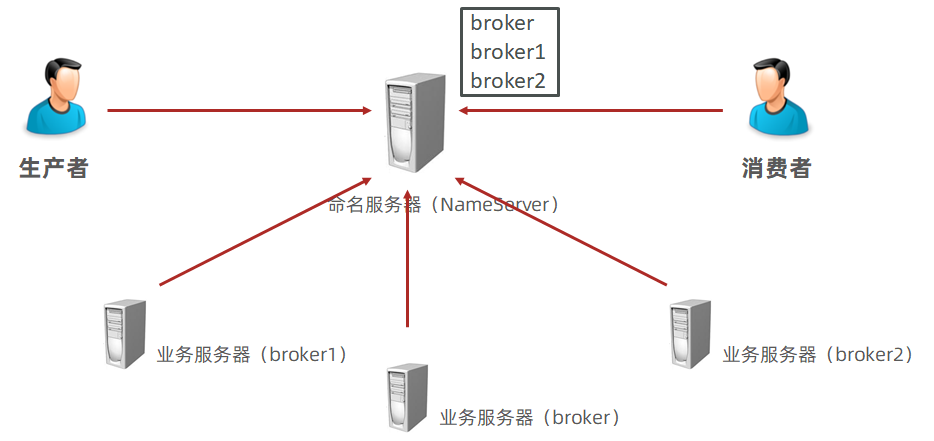
在 RocketMQ 中,处理业务的服务器称为 broker,生产者与消费者不是直接与 broker 联系的,而是通过命名服务器进行通信。broker 启动后会通知命名服务器自己已经上线,这样命名服务器中就保存有所有的 broker 信息。当生产者与消费者需要连接 broker 时,通过命名服务器找到对应的处理业务的 broker,因此命名服务器在整套结构中起到一个信息中心的作用。并且 broker 启动前必须保障命名服务器先启动。
启动服务器
1 | mqnamesrv # 启动命名服务器 |
运行 bin 目录下的 mqnamesrv 命令即可启动命名服务器,默认对外服务端口 9876。
运行 bin 目录下的 mqbroker 命令即可启动 broker 服务器,如果环境变量中没有设置 NAMESRV_ADDR 则需要在运行 mqbroker 指令前通过 set 指令设置 NAMESRV_ADDR 的值,并且每次开启均需要设置此项。
测试服务器启动状态
RocketMQ 提供有一套测试服务器功能的测试程序,运行 bin 目录下的 tools 命令即可使用。
1 | tools org.apache.rocketmq.example.quickstart.Producer # 生产消息 |
# 整合(异步消息)
步骤①:导入 springboot 整合 RocketMQ 的 starter,此坐标不由 springboot 维护版本
1 | <dependency> |
步骤②:配置 RocketMQ 的服务器地址
1 | rocketmq: |
设置默认的生产者消费者所属组 group。
步骤③:使用 RocketMQTemplate 操作 RocketMQ
1 |
|
使用 asyncSend 方法发送异步消息。
步骤④:使用消息监听器在服务器启动后,监听指定位置,当消息出现后,立即消费消息
1 |
|
RocketMQ 的监听器必须按照标准格式开发,实现 RocketMQListener 接口,泛型为消息类型。
使用注解 @RocketMQMessageListener 定义当前类监听 RabbitMQ 中指定组、指定名称的消息队列。
总结
- springboot 整合 RocketMQ 使用 RocketMQTemplate 对象作为客户端操作消息队列
- 操作 RocketMQ 需要配置 RocketMQ 服务器地址,默认端口 9876
- 企业开发时通常使用监听器来处理消息队列中的消息,设置监听器使用注解 @RocketMQMessageListener
# SpringBoot 整合 Kafka
# 安装
windows 版安装包下载地址:https://kafka.apache.org/downloads
下载完毕后得到 tgz 压缩文件,使用解压缩软件解压缩即可使用,解压后得到如下文件
建议使用 windows 版 2.8.1 版本。
启动服务器
kafka 服务器的功能相当于 RocketMQ 中的 broker,kafka 运行还需要一个类似于命名服务器的服务。在 kafka 安装目录中自带一个类似于命名服务器的工具,叫做 zookeeper,它的作用是注册中心,相关知识请到对应课程中学习。
1 | zookeeper-server-start.bat ..\..\config\zookeeper.properties # 启动zookeeper |
运行 bin 目录下的 windows 目录下的 zookeeper-server-start 命令即可启动注册中心,默认对外服务端口 2181。
运行 bin 目录下的 windows 目录下的 kafka-server-start 命令即可启动 kafka 服务器,默认对外服务端口 9092。
创建主题
和之前操作其他 MQ 产品相似,kakfa 也是基于主题操作,操作之前需要先初始化 topic。
1 | # 创建topic |
测试服务器启动状态
Kafka 提供有一套测试服务器功能的测试程序,运行 bin 目录下的 windows 目录下的命令即可使用。
1 | kafka-console-producer.bat --broker-list localhost:9092 --topic itheima # 测试生产消息 |
# 整合
步骤①:导入 springboot 整合 Kafka 的 starter,此坐标由 springboot 维护版本
1 | <dependency> |
步骤②:配置 Kafka 的服务器地址
1 | spring: |
设置默认的生产者消费者所属组 id。
步骤③:使用 KafkaTemplate 操作 Kafka
1 |
|
使用 send 方法发送消息,需要传入 topic 名称。
步骤④:使用消息监听器在服务器启动后,监听指定位置,当消息出现后,立即消费消息
1 |
|
使用注解 @KafkaListener 定义当前方法监听 Kafka 中指定 topic 的消息,接收到的消息封装在对象 ConsumerRecord 中,获取数据从 ConsumerRecord 对象中获取即可。
总结
-
springboot 整合 Kafka 使用 KafkaTemplate 对象作为客户端操作消息队列
-
操作 Kafka 需要配置 Kafka 服务器地址,默认端口 9092
-
企业开发时通常使用监听器来处理消息队列中的消息,设置监听器使用注解 @KafkaListener。接收消息保存在形参 ConsumerRecord 对象中
# KF-6. 监控
在说监控之前,需要回顾一下软件业的发展史。最早的软件完成一些非常简单的功能,代码不多,错误也少。随着软件功能的逐步完善,软件的功能变得越来越复杂,功能不能得到有效的保障,这个阶段出现了针对软件功能的检测,也就是软件测试。伴随着计算机操作系统的逐步升级,软件的运行状态也变得开始让人捉摸不透,出现了不稳定的状况。伴随着计算机网络的发展,程序也从单机状态切换成基于计算机网络的程序,应用于网络的程序开始出现,由于网络的不稳定性,程序的运行状态让使用者更加堪忧。互联网的出现彻底打破了软件的思维模式,随之而来的互联网软件就更加凸显出应对各种各样复杂的网络情况之下的弱小。计算机软件的运行状况已经成为了软件运行的一个大话题,针对软件的运行状况就出现了全新的思维,建立起了初代的软件运行状态监控。
什么是监控?就是通过软件的方式展示另一个软件的运行情况,运行的情况则通过各种各样的指标数据反馈给监控人员。例如网络是否顺畅、服务器是否在运行、程序的功能是否能够整百分百运行成功,内存是否够用,等等等等。
本章要讲解的监控就是对软件的运行情况进行监督,但是 springboot 程序与非 springboot 程序的差异还是很大的,为了方便监控软件的开发,springboot 提供了一套功能接口,为开发者加速开发过程。
# KF-6-1. 监控的意义
对于现代的互联网程序来说,规模越来越大,功能越来越复杂,还要追求更好的客户体验,因此要监控的信息量也就比较大了。由于现在的互联网程序大部分都是基于微服务的程序,一个程序的运行需要若干个服务来保障,因此第一个要监控的指标就是服务是否正常运行,也就是监控服务状态是否处理宕机状态。一旦发现某个服务宕机了,必须马上给出对应的解决方案,避免整体应用功能受影响。其次,由于互联网程序服务的客户量是巨大的,当客户的请求在短时间内集中达到服务器后,就会出现各种程序运行指标的波动。比如内存占用严重,请求无法及时响应处理等,这就是第二个要监控的重要指标,监控服务运行指标。虽然软件是对外提供用户的访问需求,完成对应功能的,但是后台的运行是否平稳,是否出现了不影响客户使用的功能隐患,这些也是要密切监控的,此时就需要在不停机的情况下,监控系统运行情况,日志是一个不错的手段。如果在众多日志中找到开发者或运维人员所关注的日志信息,简单快速有效的过滤出要看的日志也是监控系统需要考虑的问题,这就是第三个要监控的指标,监控程序运行日志。虽然我们期望程序一直平稳运行,但是由于突发情况的出现,例如服务器被攻击、服务器内存溢出等情况造成了服务器宕机,此时当前服务不能满足使用需要,就要将其重启甚至关闭,如果快速控制服务器的启停也是程序运行过程中不可回避的问题,这就是第四个监控项,管理服务状态。以上这些仅仅是从大的方面来思考监控这个问题,还有很多的细节点,例如上线了一个新功能,定时提醒用户续费,这种功能不是上线后马上就运行的,但是当前功能是否真的启动,如果快速的查询到这个功能已经开启,这也是监控中要解决的问题,等等。看来监控真的是一项非常重要的工作。
通过上述描述,可以看出监控很重要。那具体的监控要如何开展呢?还要从实际的程序运行角度出发。比如现在有 3 个服务支撑着一个程序的运行,每个服务都有自己的运行状态。
此时被监控的信息就要在三个不同的程序中去查询并展示,但是三个服务是服务于一个程序的运行的,如果不能合并到一个平台上展示,监控工作量巨大,而且信息对称性差,要不停的在三个监控端查看数据。如果将业务放大成 30 个,300 个,3000 个呢?看来必须有一个单独的平台,将多个被监控的服务对应的监控指标信息汇总在一起,这样更利于监控工作的开展。
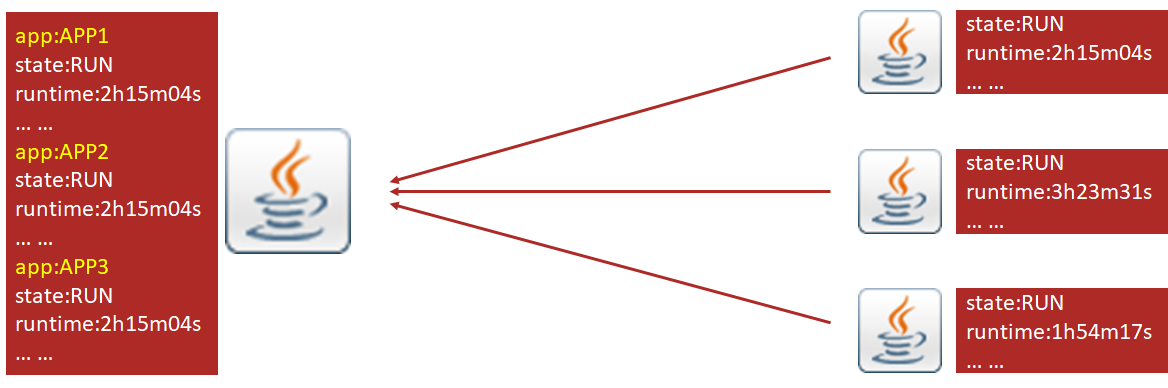
新的程序专门用来监控,新的问题就出现了,是被监控程序主动上报信息还是监控程序主动获取信息?如果监控程序不能主动获取信息,这就意味着监控程序有可能看到的是很久之前被监控程序上报的信息,万一被监控程序宕机了,监控程序就无法区分究竟是好久没法信息了,还是已经下线了。所以监控程序必须具有主动发起请求获取被监控服务信息的能力。

如果监控程序要监控服务时,主动获取对方的信息。那监控程序如何知道哪些程序被自己监控呢?不可能在监控程序中设置我监控谁,这样互联网上的所有程序岂不是都可以被监控到,这样的话信息安全将无法得到保障。合理的做法只能是在被监控程序启动时上报监控程序,告诉监控程序你可以监控我了。看来需要在被监控程序端做主动上报的操作,这就要求被监控程序中配置对应的监控程序是谁。
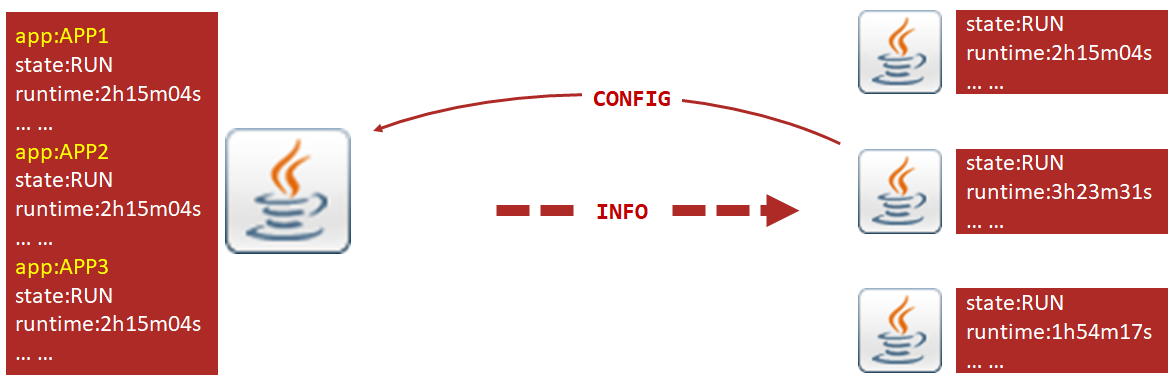
被监控程序可以提供各种各样的指标数据给监控程序看,但是每一个指标都代表着公司的机密信息,并不是所有的指标都可以给任何人看的,乃至运维人员,所以对被监控指标的是否开放出来给监控系统看,也需要做详细的设定。
以上描述的整个过程就是一个监控系统的基本流程。
总结
- 监控是一个非常重要的工作,是保障程序正常运行的基础手段
- 监控的过程通过一个监控程序进行,它汇总所有被监控的程序的信息集中统一展示
- 被监控程序需要主动上报自己被监控,同时要设置哪些指标被监控
思考
下面就要开始做监控了,新的问题就来了,监控程序怎么做呢?难道要自己写吗?肯定是不现实的,如何进行监控,咱们下节再讲。
# KF-6-2. 可视化监控平台
springboot 抽取了大部分监控系统的常用指标,提出了监控的总思想。然后就有好心的同志根据监控的总思想,制作了一个通用性很强的监控系统,因为是基于 springboot 监控的核心思想制作的,所以这个程序被命名为 Spring Boot Admin。
Spring Boot Admin,这是一个开源社区项目,用于管理和监控 SpringBoot 应用程序。这个项目中包含有客户端和服务端两部分,而监控平台指的就是服务端。我们做的程序如果需要被监控,将我们做的程序制作成客户端,然后配置服务端地址后,服务端就可以通过 HTTP 请求的方式从客户端获取对应的信息,并通过 UI 界面展示对应信息。
下面就来开发这套监控程序,先制作服务端,其实服务端可以理解为是一个 web 程序,收到一些信息后展示这些信息。
服务端开发
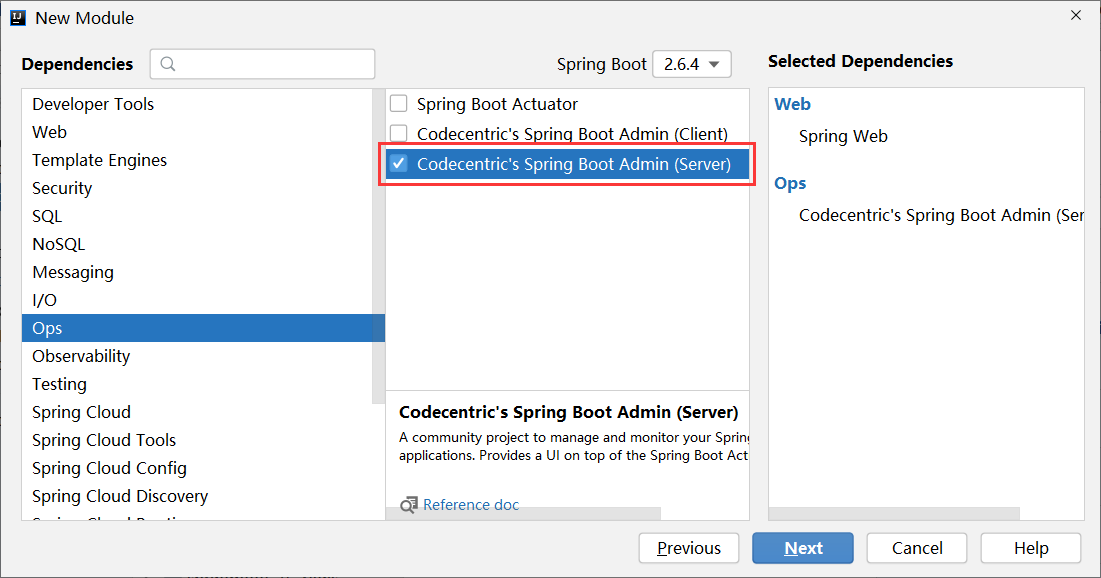
步骤①:导入 springboot admin 对应的 starter,版本与当前使用的 springboot 版本保持一致,并将其配置成 web 工程
1 | <dependency> |
上述过程可以通过创建项目时使用勾选的形式完成。
步骤②:在引导类上添加注解 @EnableAdminServer,声明当前应用启动后作为 SpringBootAdmin 的服务器使用
1 |
|
做到这里,这个服务器就开发好了,启动后就可以访问当前程序了,界面如下。
由于目前没有启动任何被监控的程序,所以里面什么信息都没有。下面制作一个被监控的客户端程序。
客户端开发
客户端程序开发其实和服务端开发思路基本相似,多了一些配置而已。
步骤①:导入 springboot admin 对应的 starter,版本与当前使用的 springboot 版本保持一致,并将其配置成 web 工程
1 | <dependency> |
上述过程也可以通过创建项目时使用勾选的形式完成,不过一定要小心,端口配置成不一样的,否则会冲突。
步骤②:设置当前客户端将信息上传到哪个服务器上,通过 yml 文件配置
1 | spring: |
做到这里,这个客户端就可以启动了。启动后再次访问服务端程序,界面如下。
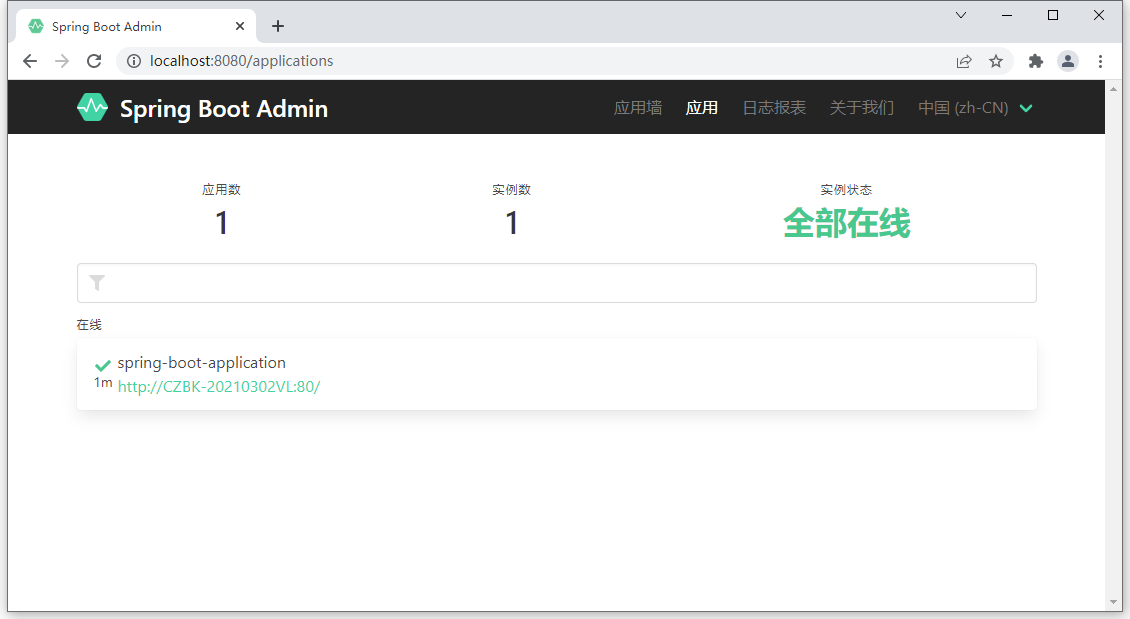
可以看到,当前监控了 1 个程序,点击进去查看详细信息。
由于当前没有设置开放哪些信息给监控服务器,所以目前看不到什么有效的信息。下面需要做两组配置就可以看到信息了。
-
开放指定信息给服务器看
-
允许服务器以 HTTP 请求的方式获取对应的信息
配置如下:
1 | server: |
上述配置对于初学者来说比较容易混淆。简单解释一下,到下一节再做具体的讲解。springbootadmin 的客户端默认开放了 13 组信息给服务器,但是这些信息除了一个之外,其他的信息都不让通过 HTTP 请求查看。所以你看到的信息基本上就没什么内容了,只能看到一个内容,就是下面的健康信息。
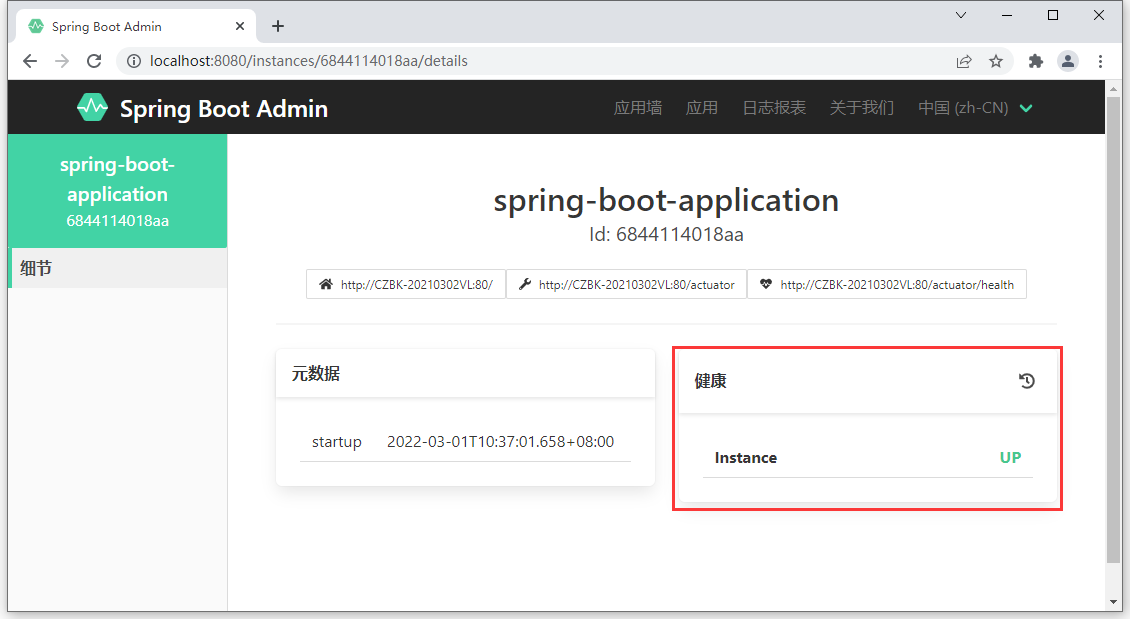
但是即便如此我们看到健康信息中也没什么内容,原因在于健康信息中有一些信息描述了你当前应用使用了什么技术等信息,如果无脑的对外暴露功能会有安全隐患。通过配置就可以开放所有的健康信息明细查看了。
1 | management: |
健康明细信息如下:
目前除了健康信息,其他信息都查阅不了。原因在于其他 12 种信息是默认不提供给服务器通过 HTTP 请求查阅的,所以需要开启查阅的内容项,使用 * 表示查阅全部。记得带引号。
1 | endpoints: |
配置后再刷新服务器页面,就可以看到所有的信息了。
以上界面中展示的信息量就非常大了,包含了 13 组信息,有性能指标监控,加载的 bean 列表,加载的系统属性,日志的显示控制等等。
配置多个客户端
可以通过配置客户端的方式在其他的 springboot 程序中添加客户端坐标,这样当前服务器就可以监控多个客户端程序了。每个客户端展示不同的监控信息。
进入监控面板,如果你加载的应用具有功能,在监控面板中可以看到 3 组信息展示的与之前加载的空工程不一样。
- 类加载面板中可以查阅到开发者自定义的类,如左图
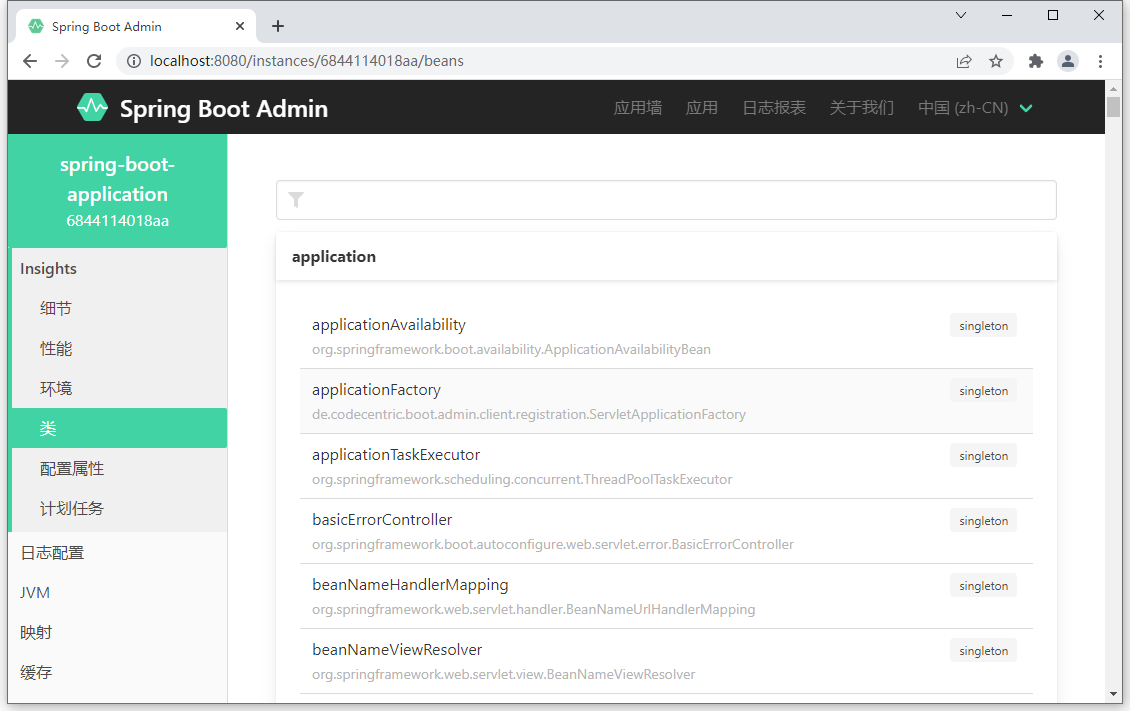
- 映射中可以查阅到当前应用配置的所有请求
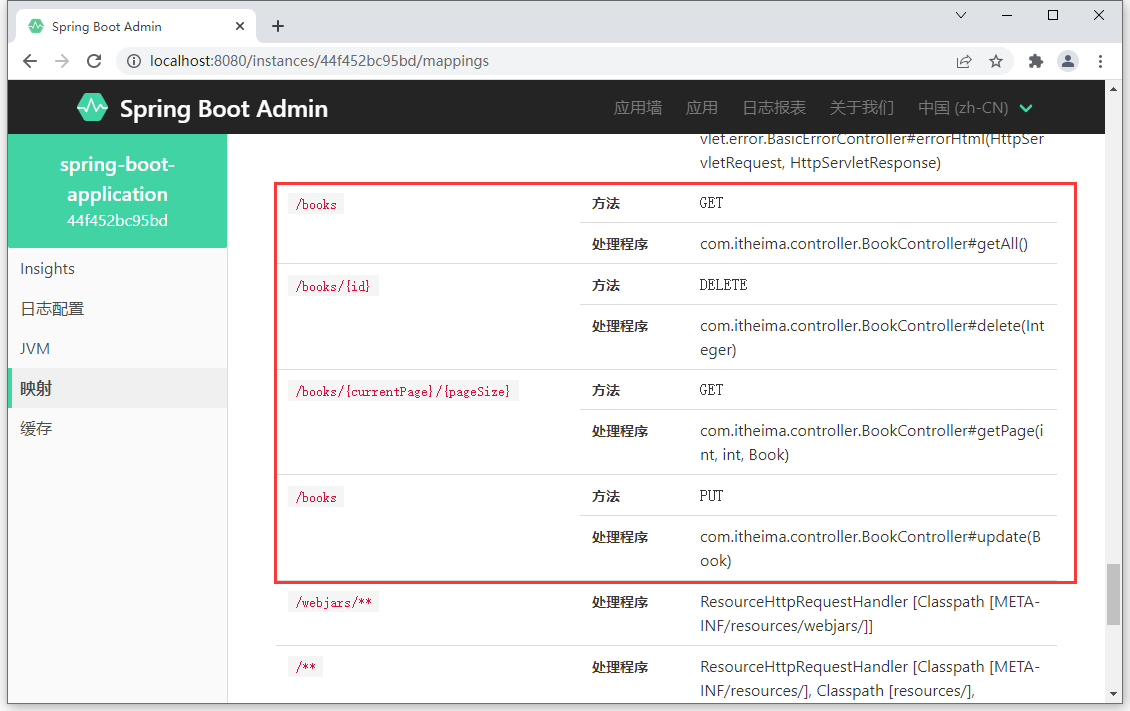
- 性能指标中可以查阅当前应用独有的请求路径统计数据
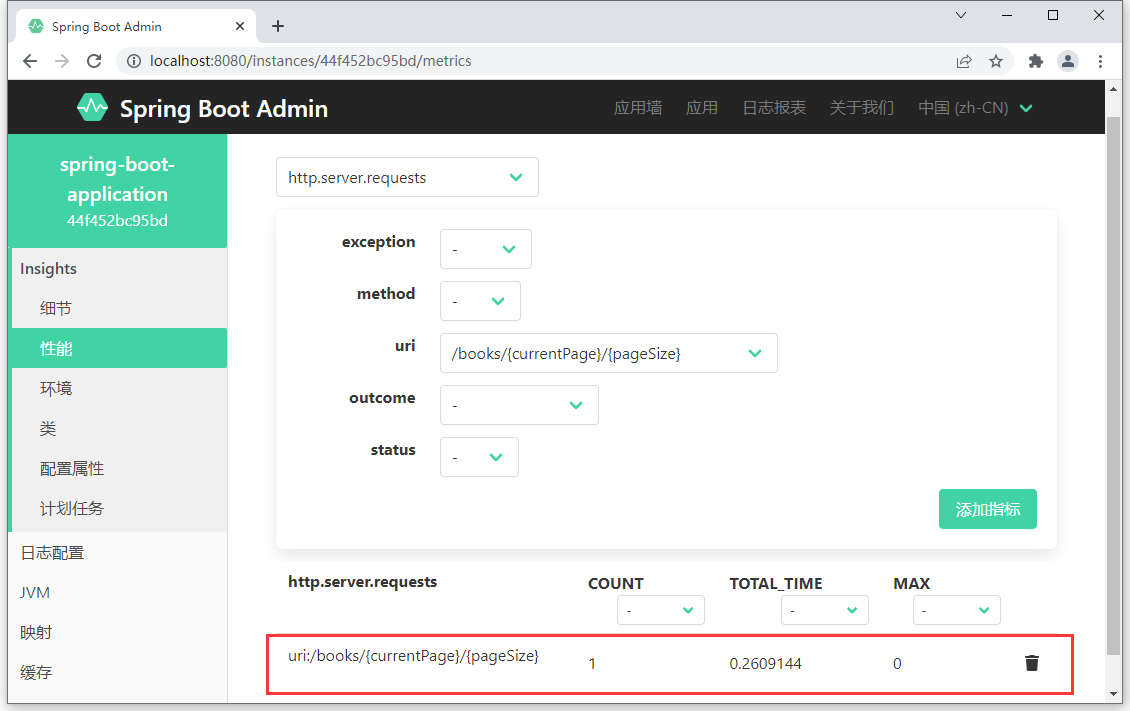
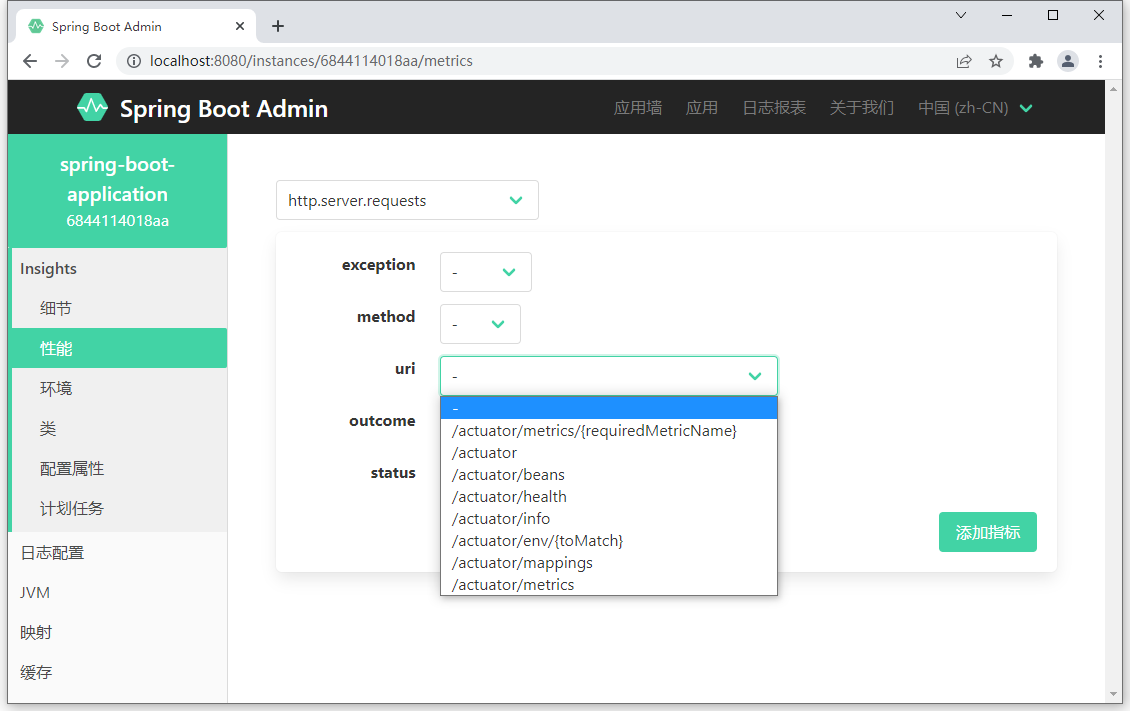
总结
- 开发监控服务端需要导入坐标,然后在引导类上添加注解 @EnableAdminServer,并将其配置成 web 程序即可
- 开发被监控的客户端需要导入坐标,然后配置服务端服务器地址,并做开放指标的设定即可
- 在监控平台中可以查阅到各种各样被监控的指标,前提是客户端开放了被监控的指标
思考
之前说过,服务端要想监控客户端,需要主动的获取到对应信息并展示出来。但是目前我们并没有在客户端开发任何新的功能,但是服务端确可以获取监控信息,谁帮我们做的这些功能呢?咱们下一节再讲。
# KF-6-3. 监控原理
通过查阅监控中的映射指标,可以看到当前系统中可以运行的所有请求路径,其中大部分路径以 /actuator 开头
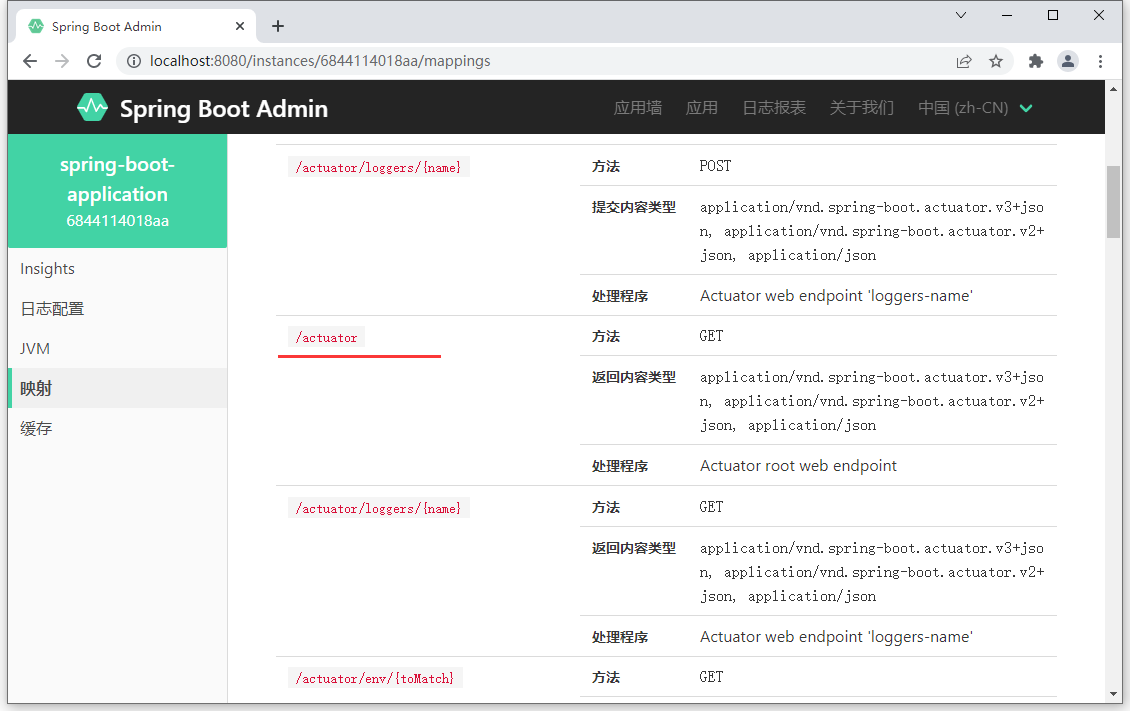
首先这些请求路径不是开发者自己编写的,其次这个路径代表什么含义呢?既然这个路径可以访问,就可以通过浏览器发送该请求看看究竟可以得到什么信息。
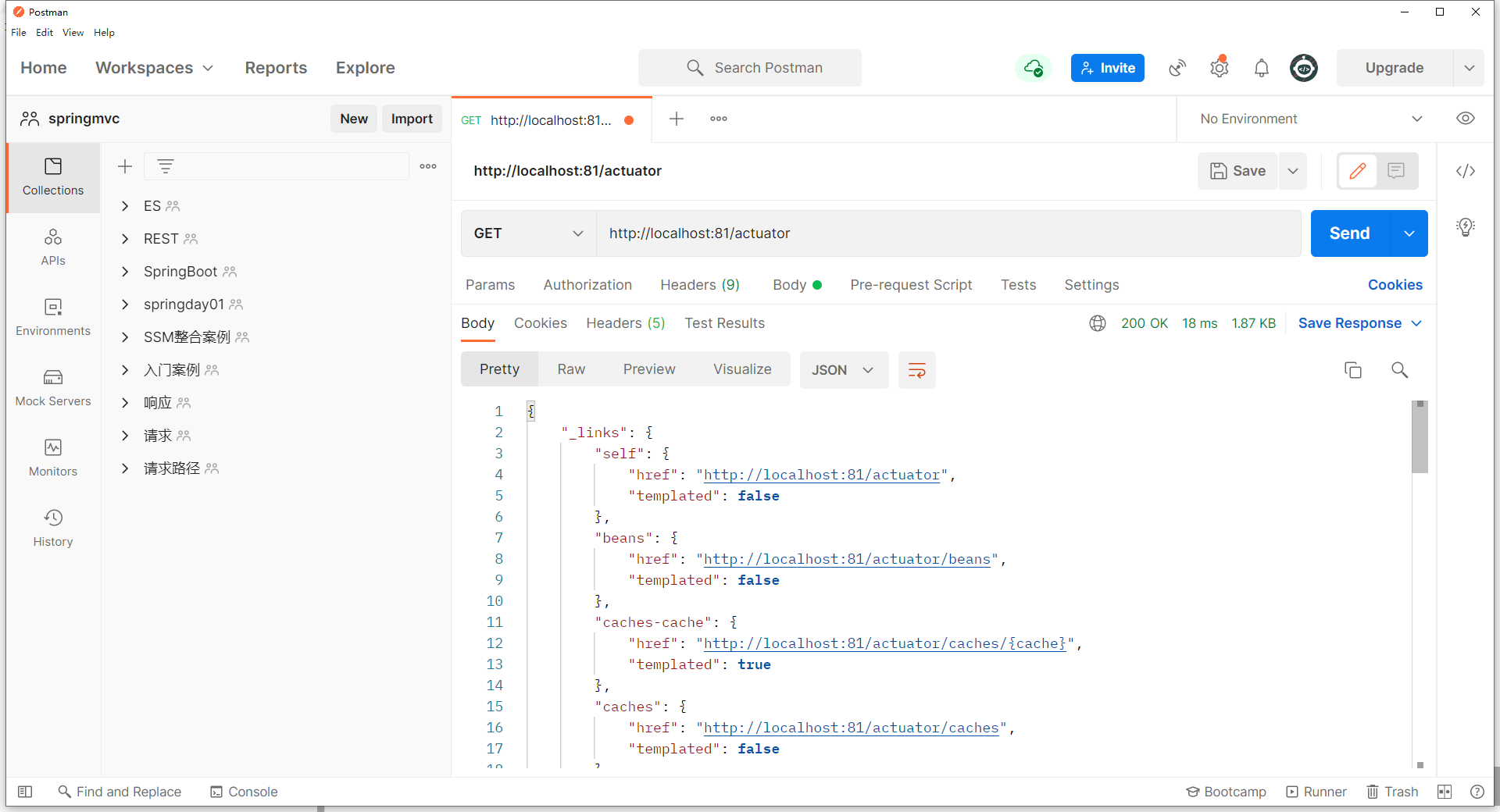
通过发送请求,可以得到一组 json 信息,如下
1 | { |
其中每一组数据都有一个请求路径,而在这里请求路径中有之前看到过的 health,发送此请求又得到了一组信息
1 | { |
当前信息与监控面板中的数据存在着对应关系
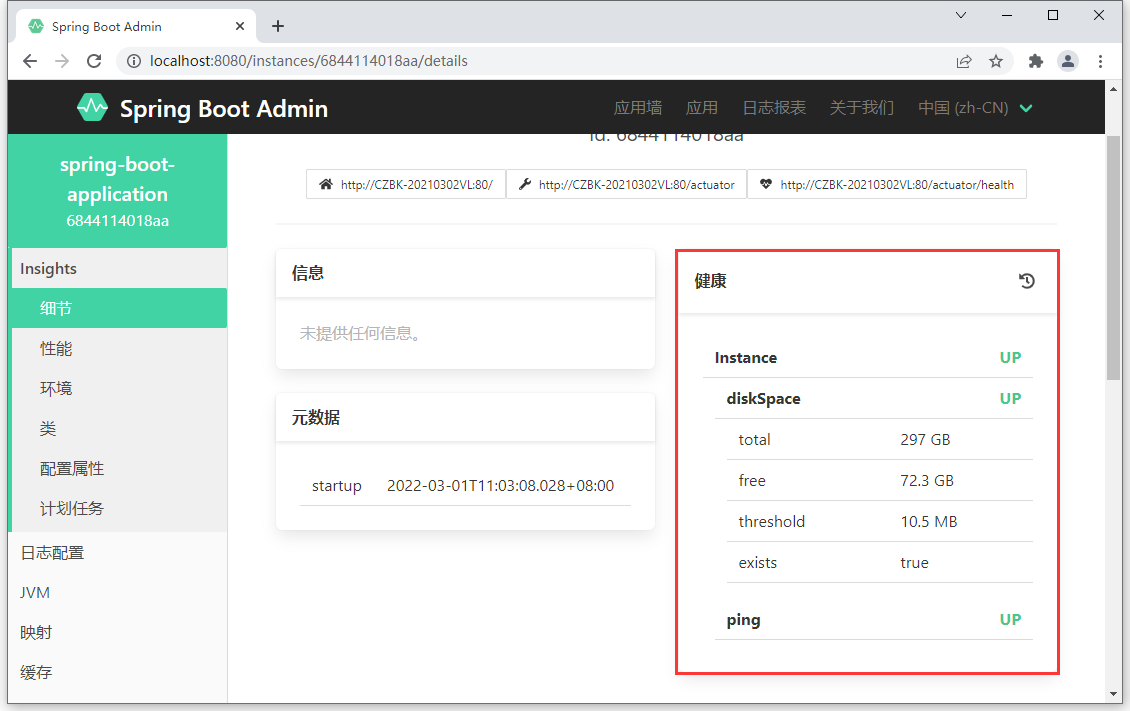
原来监控中显示的信息实际上是通过发送请求后得到 json 数据,然后展示出来。按照上述操作,可以发送更多的以 /actuator 开头的链接地址,获取更多的数据,这些数据汇总到一起组成了监控平台显示的所有数据。
到这里我们得到了一个核心信息,监控平台中显示的信息实际上是通过对被监控的应用发送请求得到的。那这些请求谁开发的呢?打开被监控应用的 pom 文件,其中导入了 springboot admin 的对应的 client,在这个资源中导入了一个名称叫做 actuator 的包。被监控的应用之所以可以对外提供上述请求路径,就是因为添加了这个包。
这个 actuator 是什么呢?这就是本节要讲的核心内容,监控的端点。
Actuator,可以称为端点,描述了一组监控信息,SpringBootAdmin 提供了多个内置端点,通过访问端点就可以获取对应的监控信息,也可以根据需要自定义端点信息。通过发送请求路劲 **/actuator 可以访问应用所有端点信息,如果端点中还有明细信息可以发送请求 /actuator/ 端点名称 ** 来获取详细信息。以下列出了所有端点信息说明:
| ID | 描述 | 默认启用 |
|---|---|---|
| auditevents | 暴露当前应用程序的审计事件信息。 | 是 |
| beans | 显示应用程序中所有 Spring bean 的完整列表。 | 是 |
| caches | 暴露可用的缓存。 | 是 |
| conditions | 显示在配置和自动配置类上评估的条件以及它们匹配或不匹配的原因。 | 是 |
| configprops | 显示所有 @ConfigurationProperties 的校对清单。 | 是 |
| env | 暴露 Spring ConfigurableEnvironment 中的属性。 | 是 |
| flyway | 显示已应用的 Flyway 数据库迁移。 | 是 |
| health | 显示应用程序健康信息 | 是 |
| httptrace | 显示 HTTP 追踪信息(默认情况下,最后 100 个 HTTP 请求 / 响应交换)。 | 是 |
| info | 显示应用程序信息。 | 是 |
| integrationgraph | 显示 Spring Integration 图。 | 是 |
| loggers | 显示和修改应用程序中日志记录器的配置。 | 是 |
| liquibase | 显示已应用的 Liquibase 数据库迁移。 | 是 |
| metrics | 显示当前应用程序的指标度量信息。 | 是 |
| mappings | 显示所有 @RequestMapping 路径的整理清单。 | 是 |
| scheduledtasks | 显示应用程序中的调度任务。 | 是 |
| sessions | 允许从 Spring Session 支持的会话存储中检索和删除用户会话。当使用 Spring Session 的响应式 Web 应用程序支持时不可用。 | 是 |
| shutdown | 正常关闭应用程序。 | 否 |
| threaddump | 执行线程 dump。 | 是 |
| heapdump | 返回一个 hprof 堆 dump 文件。 | 是 |
| jolokia | 通过 HTTP 暴露 JMX bean(当 Jolokia 在 classpath 上时,不适用于 WebFlux)。 | 是 |
| logfile | 返回日志文件的内容(如果已设置 logging.file 或 logging.path 属性)。支持使用 HTTP Range 头来检索部分日志文件的内容。 | 是 |
| prometheus | 以可以由 Prometheus 服务器抓取的格式暴露指标。 | 是 |
上述端点每一项代表被监控的指标,如果对外开放则监控平台可以查询到对应的端点信息,如果未开放则无法查询对应的端点信息。通过配置可以设置端点是否对外开放功能。使用 enable 属性控制端点是否对外开放。其中 health 端点为默认端点,不能关闭。
1 | management: |
为了方便开发者快速配置端点,springboot admin 设置了 13 个较为常用的端点作为默认开放的端点,如果需要控制默认开放的端点的开放状态,可以通过配置设置,如下:
1 | management: |
上述端点开启后,就可以通过端点对应的路径查看对应的信息了。但是此时还不能通过 HTTP 请求查询此信息,还需要开启通过 HTTP 请求查询的端点名称,使用 “*” 可以简化配置成开放所有端点的 WEB 端 HTTP 请求权限。
1 | management: |
整体上来说,对于端点的配置有两组信息,一组是 endpoints 开头的,对所有端点进行配置,一组是 endpoint 开头的,对具体端点进行配置。
1 | management: |
总结
-
被监控客户端通过添加 actuator 的坐标可以对外提供被访问的端点功能
-
端点功能的开放与关闭可以通过配置进行控制
-
web 端默认无法获取所有端点信息,通过配置开放端点功能
# KF-6-4. 自定义监控指标
端点描述了被监控的信息,除了系统默认的指标,还可以自行添加显示的指标,下面就通过 3 种不同的端点的指标自定义方式来学习端点信息的二次开发。
INFO 端点
info 端点描述了当前应用的基本信息,可以通过两种形式快速配置 info 端点的信息
-
配置形式
在 yml 文件中通过设置 info 节点的信息就可以快速配置端点信息
1
2
3
4
5info:
appName: @project.artifactId@
version: @project.version@
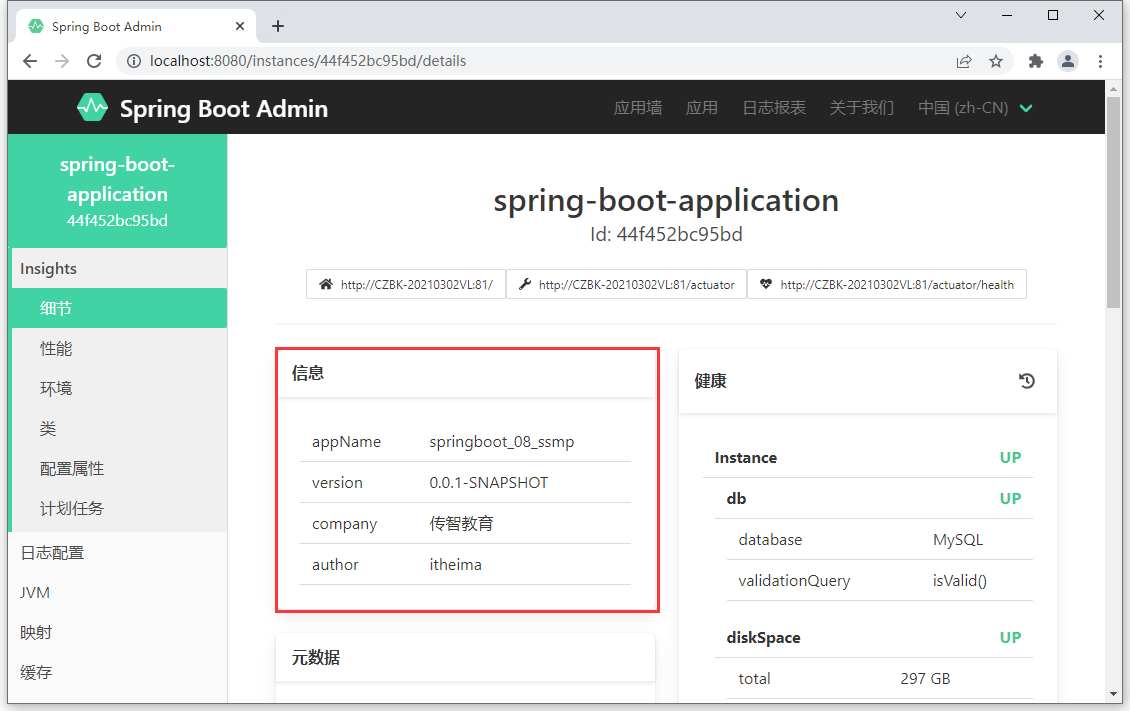
company: 传智教育
author: itheima配置完毕后,对应信息显示在监控平台上
也可以通过请求端点信息路径获取对应 json 信息
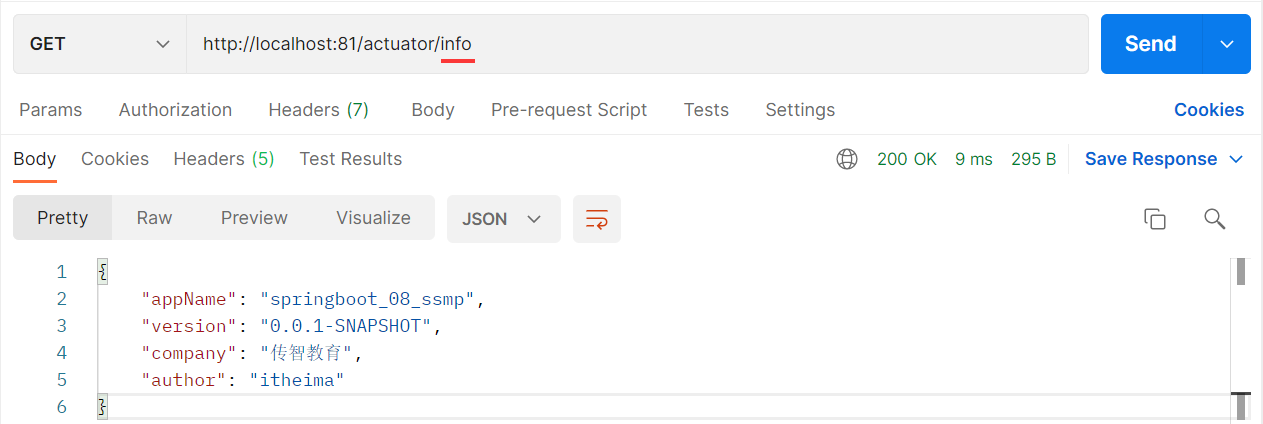
-
编程形式
通过配置的形式只能添加固定的数据,如果需要动态数据还可以通过配置 bean 的方式为 info 端点添加信息,此信息与配置信息共存
1
2
3
4
5
6
7
8
9
10
public class InfoConfig implements InfoContributor {
public void contribute(Info.Builder builder) {
builder.withDetail("runTime",System.currentTimeMillis()); //添加单个信息
Map infoMap = new HashMap();
infoMap.put("buildTime","2006");
builder.withDetails(infoMap); //添加一组信息
}
}
Health 端点
health 端点描述当前应用的运行健康指标,即应用的运行是否成功。通过编程的形式可以扩展指标信息。
1 |
|
当任意一个组件状态不为 UP 时,整体应用对外服务状态为非 UP 状态。
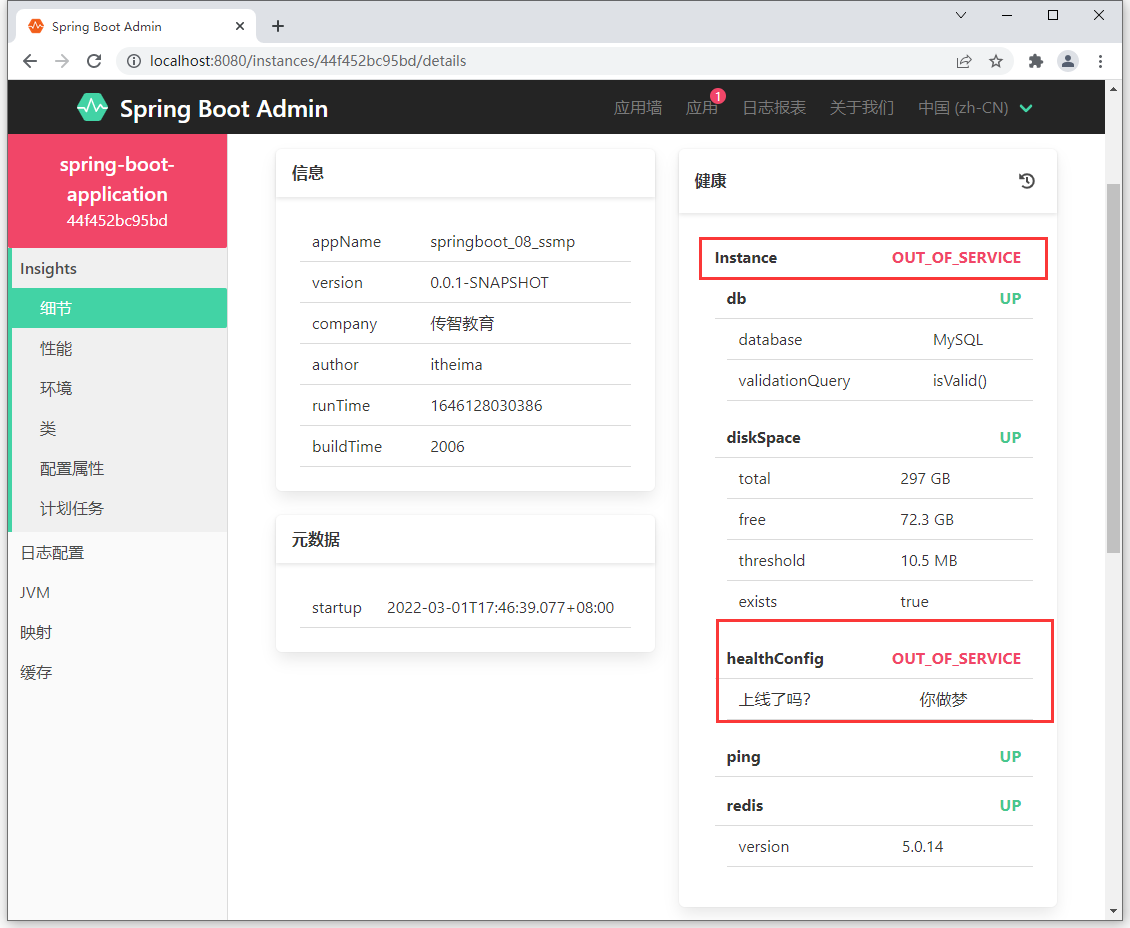
Metrics 端点
metrics 端点描述了性能指标,除了系统自带的监控性能指标,还可以自定义性能指标。
1 |
|
在性能指标中就出现了自定义的性能指标监控项
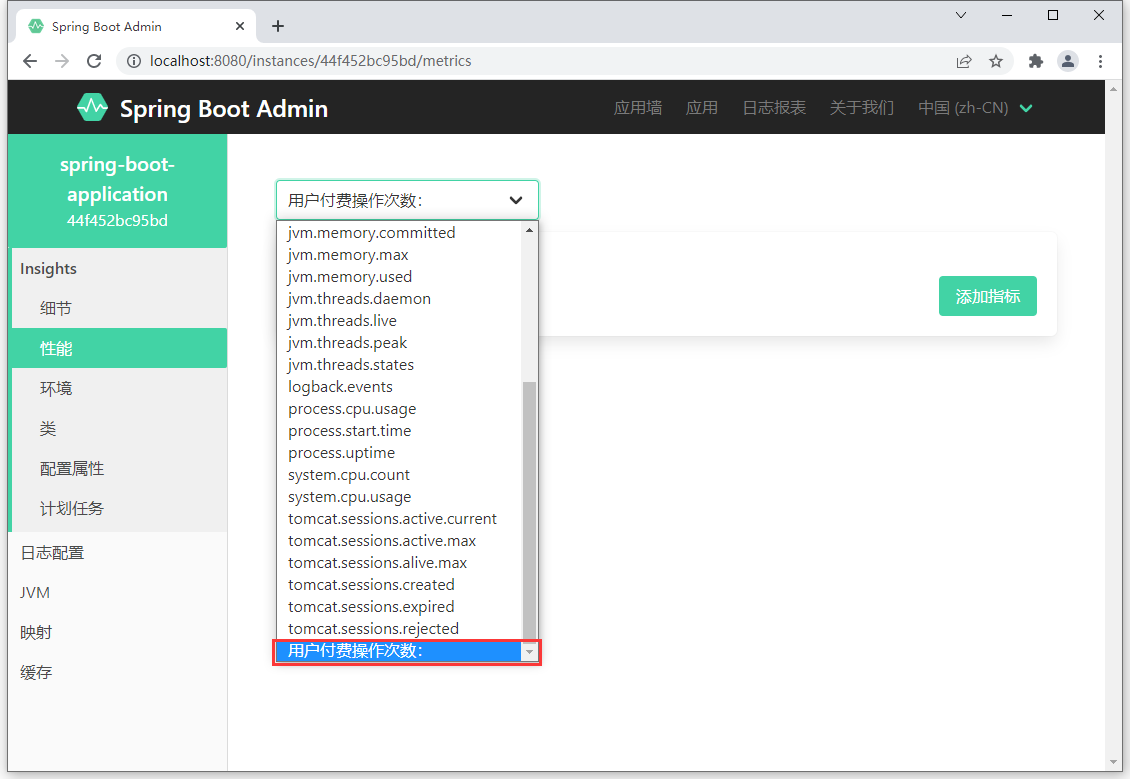
自定义端点
可以根据业务需要自定义端点,方便业务监控
1 |
|
由于此端点数据 spirng boot admin 无法预知该如何展示,所以通过界面无法看到此数据,通过 HTTP 请求路径可以获取到当前端点的信息,但是需要先开启当前端点对外功能,或者设置当前端点为默认开发的端点。
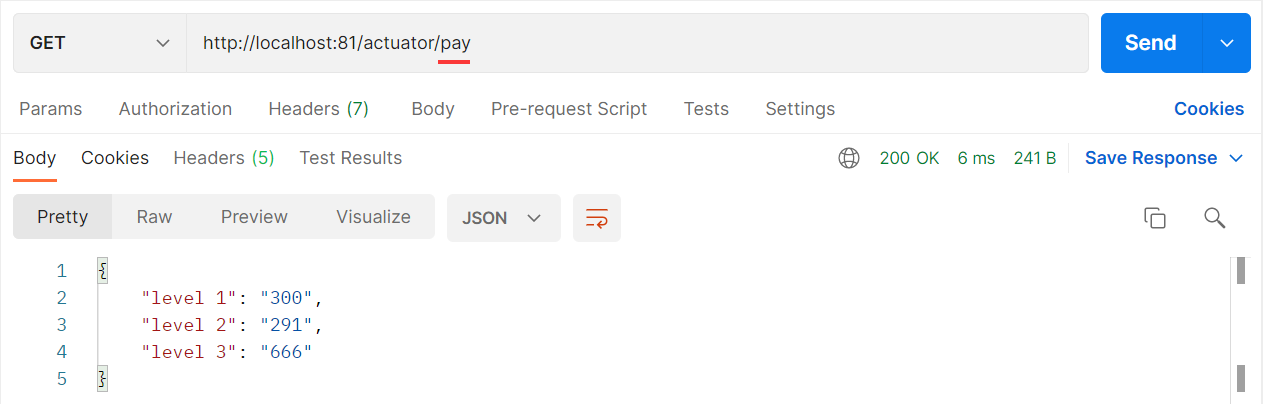
总结
- 端点的指标可以自定义,但是每种不同的指标根据其功能不同,自定义方式不同
- info 端点通过配置和编程的方式都可以添加端点指标
- health 端点通过编程的方式添加端点指标,需要注意要为对应指标添加启动状态的逻辑设定
- metrics 指标通过在业务中添加监控操作设置指标
- 可以自定义端点添加更多的指标
# 开发实用篇完结
开发实用篇到这里就暂时完结了,在开发实用篇中我们讲解了大量的第三方技术的整合方案,选择的方案都是市面上比较流行的常用方案,还有一些国内流行度较低的方案目前还没讲,留到番外篇中慢慢讲吧。
整体开发实用篇中讲解的内容可以分为两大类知识:实用性知识与经验性知识。
实用性知识就是新知识了,springboot 整合各种技术,每种技术整合中都有一些特殊操作,整体来说其实就是三句话。加坐标做配置调接口。经验性知识是对前面两篇中出现的一些知识的补充,在学习基础篇时如果将精力放在这些东西上就有点学偏了,容易钻牛角尖,放到实用开发篇中结合实际开发说一些不常见的但是对系统功能又危害的操作解决方案,提升理解。
开发实用篇做到这里就告一段落,下面就要着手准备原理篇了。市面上很多课程原理篇讲的过于高深莫测,在新手还没明白 123 的时候就开始讲微积分了,着实让人看了着急。至于原理篇我讲成什么样子?一起期待吧。
 微信
微信 QQ
QQ 支付宝
支付宝








